Basic Data Pre-processing of 21,085 labeled utterances
Data pre-processing is an important step in data mining process. Due to data-gathering method are usually loosely controlled, it is easily resulting in missing values, duplicate data entry, data entry contains invalid symbol, etc. Analyzing on noisy and unreliable data is likely to produce misleading result. Thus, data pre-processing, which includes cleaning, normalization, transformation, feature extraction and selection, can enhance the quality of data.
There were 700 data entry labeled by multiple evaluators. It is necessary to remove these duplicate entries and keep unique entry in the corpus for future data post-processing. Unix shell script was used to eliminate identical entry. As for entry with missing values or contains invalid symbol (i.e. non alphanumeric characters), manual adjustment has been done to ensure entry is a valid input for further analysis.
In addition, statistical distribution analysis was performed. The fluency distribution is shown in Figure 1.
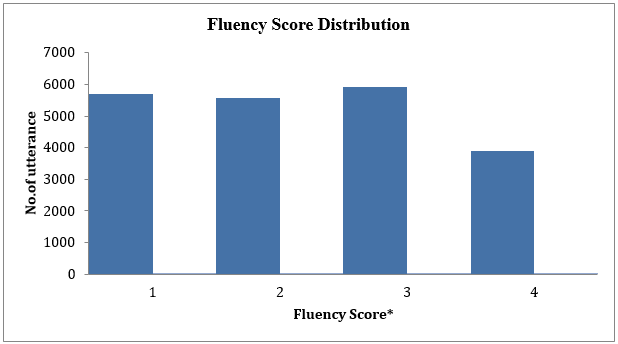
Figure 1 Fluency Score Distribution
Fluency Score*: 1 is the lowest and 4 is the highest.
The above figure shows the number of utterances is almost evenly distributed over a fix interval of fluency score. This implies that each fluency score category has equal amount of training data, which reduces the analysis inaccuracy due to the amount of data imbalance.