FCG is an open-source software that enables linguists to play around with an inventory of construction grammar in order to test out theories and experiments related to the studies of language learning and evolution. To simply explain the flow: grammarians hypothesise or theorise how a language’s grammar could probably work, insert an inventory of words into the software, and then let the software compute the outcome of their theory. This computation is achieved through the use of templates (of grammar theories). For example, say a researcher theorised that the English language follows the syntactic structure of Subject-Verb-Object (object). An example sentence would flow like so: “John (subject) kicked (verb) the ball (object)”.
How then could the researcher test and verify if this theory is plausible? He or she would then create a template (through the software) of how the theory would work, insert an inventory of words that can be real or made up, then let the software run through all possible construction combinations until the last option is exhausted. The whole process is called a “transient structure”, where constructions are executed in a systematic fashion up to a point where nothing further can be worked out (Schneider & Tsarfaty, 2013). It works somewhat like how engineers, scientists, historians or similar researchers utilise predictive software to predict the possible outcomes of something they plan to do, or reverse engineer to find out how something came to be.
In a nutshell, Fluid Construction Grammar is basically application of artificial intelligence to construction grammar (van Trijp, 2013). It has grown from strength to strength, drawing from many fields of linguistics as research grows more sophisticated over the years, to become the FCG we use today. Steels eventually discovered that language is itself a master of acclimatisation, able to adjust accordingly in real time to interaction between interlocutors, instead of a fixed communication system that interlocutors adhere to as advocated by Chomsky (Van Trijp, 2013).
–Design Patterns in FCG
There are certain design aspects of FCG worth noting, as introduced by Schneider & Tsarfaty (2013).
Firstly, some of the winning factors and selling points of FCG is that the scaffold of its system is sturdy and smoothly flexible. It was designed to be a schema for descriptive linguistic study hoping to investigate and educate on language change and progression.
Also, the software uses templates so that the researcher does not have to code or create anything from scratch – they just have to choose their parameters offered from the software.
According to Luc Steels, the creator of FCG, the flow of processing moves from lower-level linguistic units to higher-level phrasal units. That is, the software would first deal with simple combinations consisting of articles and single words (for example, the dog) and exhaust all iterations before moving to creating constructions in phrases (for example, the huge fluffy dog). Initial constructions come together to make up default ordered grammatical structures before supplementary constructions enforce further limitations that influence yet more resulting structure possibilities.
Next comes the more detailed workings of FCG – that which concerns the matching of elements between semantic and syntactic constituents; certainly no easy feat since each world language has its own systems of matching and producing these instances. The way FCG navigates through this huge pool of possibilities is by not limiting any default outcome at all – every lexical item can be assigned any potential constituent. It is only when constructions are applied that matches are made, in order to produce resulting phrasal structures. In other words, if we were to take the example sentence provided earlier (“John kicked the ball”) it is completely valid to also create a sentence which flows like “John kicked the kitchen” or like “Kitchen balled the John” and so on. Words that are traditionally verbs could take on the role of a subject or noun, and vice versa. Whether the semantic meaning makes sense does not matter at this stage; researchers would analyse and deduce conclusions after every possible construction has been formed. This method hence juxtaposes with the traditional generative grammar approach which often prescribes all constituent matches from the starting point. The resulting advantage that
FCG can boast over generative grammar is thus its facility to compute many more new constructions in languages/words it had yet been introduced to and deliver more instances of manipulation of constructions.
One more aspect worth noting is that despite the default setting described early of open and unrestrained application of constructions, FCG also allows for pre-set templates. These templates are also a demonstration of the frequencies of certain constructions. This is made possible through scoring of constructions ranging from favourable to common. That is, the software scores the tendency of certain templates being used. This allows an overall macro look at whether there are emerging patterns of certain grammatical constructions being preferred and help to improve efficiency in choosing templates for computation.
–Application: FCG Case Study (Spanish L2)
There has been an FCG case study conducted on L2 Spanish verb morphology where the software was investigated/measured for accuracy, operationally defined as “the percentage of corrected forms that equals the human correction” (Beuls, 2014, p. 14). That is, the researchers would test and see what FCG offers up as the correct answer for verb conjugations, and compare those results with what a human L1 Spanish speaker will correct the answer with. In summary, FCG scored a 58% average on the complete sub-corpus, further broken down into 52% accuracy against low-intermediate level lexical items and 63% accuracy against the advanced lexical items. The research also suggested that FCG performed better with the mistakes of advanced Spanish L2 learners. When refined for enhanced accuracy i.e. corrections made by FCG on isolated lexical forms the software improved slightly to a score of 70% accuracy and the discrepancy between the two learning levels vanished.
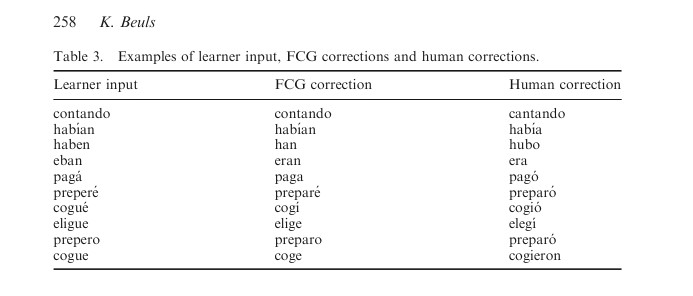
Figure 1
For further credibility they then compared the accuracy of the FCG’s results with what a word processing software would answer to see how similar they are in assessing the correctness of human grammatical constructions. The FCG’s performance was pit against the Microsoft Word spellcheck wherein the latter scored 30%, significantly lower than the FCG. This implies that the FCG’s reliability to compute constructions naturally (that is, in a humanistic way) is relatively credible and hence a tool worth considering for large scale language evolution studies.

Figure 2