Contents
1.1 Introduction
Computational simulation has been used in various disciplines to study different natural phenomena and the use of this method has also been extended to the study of language evolution (Gong, 2009). Formal models have provided invaluable insight about the emergence of various phenomena such as the emergence of communication, categorizations of percepts, lexicon formation, and grammar formation. But what exactly is a formal model? It is a precise description of a system that is based on logic and mathematics to help us algorithmically and mechanically predict the system’s behavior from its description (Smith, 2012). There are concepts within this model (usually based on our assumptions) and the models prove properties of that concept (Nallaperumal & Annam, 2013). Thus, these systems produce replicable results. They are very precise and reliable, due to the use of equations which are essentially mathematical proofs. As we will see later, these computational models are built on sound assumptions and empirical findings (Gong, 2009; Smith, 2012). In addition, the ability of the models to incorporate a high degree of realism as well as the well-defined procedures involved in studies involving these models allow for convincing results which can be replicated. Results of studies involving computational simulation can hence be used to validate assumptions, hypotheses and theories.
Formal models are used to create autonomous computer programs (these are called “agents”), which are given special characteristics such as a physical body (i.e., they are “embodied”) and placed in certain environments. We observe how these embodied agents respond to situational changes and to other agents, and communication usually arises as a side effect of such an interaction. Examples of embodied agents include physical robots or simulated computer models. After the experiment is complete, statistics are drawn, interpreted and conclusions are drawn (Nallaperumal & Annam, 2013).
1.2 Advantages of using formal models in language evolution studies
1.2.1 Formal models test the validity of theories and hypotheses
Formal models complements traditional study methods by acting as a validity test for theories and hypotheses founded on limited empirical findings or unreliable assumptions. Our assumptions lead us to create verbal descriptions which may be robust in theory; however, more importantly, we want our assumptions to match up with real world data (Smith, 2012). By demonstrating how the theories and hypotheses work, formal models can help researchers to identify problems in the theories and to modify them (Gong, 2009; Smith, 2012). This is especially important for previous theories which are often vague and were difficult to test empirically (Gong, 2009). Moreover, the building of the simulation models also aids researchers in ensuring that their theories are detailed and complete (Cangelosi & Parisi, 2002) as any inconsistencies in the theories will cause the models to malfunction and crash (Mareschal & Thomas, 2006).
Designing a formal model to be programmed into an embodied agent requires working backwards. What does real-world data look like? How can we recreate these results in mathematical terms? Formal models thus compel us to reflect on the assumptions that we want to programme into our machine mind. These assumptions not only have to be grounded in empirical evidence, but the phenomenon that we are trying to investigate should also be well-understood (Smith, 2012). Due to the repeatability of formal models, we can results mean that of what assumptions are right, which should be modified, and which are wrong and should be discarded.
1.2.2 Formal modelling compels a rigorous definition of its components
Human language is a very complex system. As evolutionary linguists attempt to explain such a complex system, verbal theories become less reliable. This is because there is now a need to explore the consequences of a given set of assumptions, and this is where formal models come in useful (Smith, 2012). This is not to say that verbal theories should be discarded. They should work alongside formal models in the creation of embodied experiments. This can be explained by the fact that formal models require interpretation of results. It is not obvious what conclusions can be drawn from a simulation experiment at times. Hence, we need verbal definitions to help us move from numerical results towards making abstract generalizations about linguistic phenomena. These phenomena will necessarily hold true given the set of assumptions.
1.2.3 Formal models help us gain insight
As mentioned by Karl Sigmund, the insight offered by a formal model could be more important than the predictions that it generates (Sigmund, 1995; Smith, 2012). While he was not entirely transparent about what this meant, we can extrapolate that manipulation of a formal model to programme it into a machine to fulfil a task, we gain a deep perception of the situation. We control such experiments by working with only one (or few) assumptions at a time. In evolutionary linguistics, dealing with multiple complex systems which interact to yield language can cause us to lose sight of the hidden processes in between. Formal models can help us elucidate some of these processes which are inherent in our assumptions. At the very least, if we fail to attain any insight of evolution from manipulating formal models, we gain insight about the structure and operation of the models themselves.
1.3 Studying language evolution through computational models
1.3.1 Modelling of various conditions and factors
Computational simulation models can be used to investigate the developmental process of language evolution. For example, studies on the emergence of language modelled different linguistic environments and had individuals programmed with some factors in order to examine whether these factors and environments could lead to the development of certain linguistic aspects (eg. Vogt 2005). This ability to manipulate various factors and conditions also allows researchers to make a comparison of results brought about by the different factors and determine which of these are necessary for the development of language. In addition, the effects of isolated factors as well as effects of sets of factors on language evolution can be studied. For example, a study done on the Baldwin Effects on the development of language isolated two factors, learning cost and cultural variation, and studied their separate effects on language (Munroe & Cangelosi, 2002).Section 1.3.2 provides an overview of the Baldwin effect as well as showing how this effect is programmed into an embodied experiment.
1.3.2 The Baldwin effect phenomenon
According to Turney, Whitley, and Anderson (1996), there were two opposing theories of evolution at the beginning of the 20th century, and it was not evident if Charles Darwin or Jean-Baptiste Lamarck explained evolution better. Lamarck believed any changes that happen to the parent could be passed right on to the offspring; while Darwin proposed that evolution could mostly be attributed to diversity and natural selection, where members of a species naturally varied from the mean by a slight margin, and only the fittest survived to pass on genetic information to the next generation (Turney, Whitley, & Anderson, 1996). A clearly identifiable distinction between the two theories was that Darwin’s supporters believed that evolution happened in small increments, in a process termed as phyletic gradualism, while Lamarck’s supporters believed that changes would occur sporadically and drastically (Turney, Whitley, & Anderson, 1996). Lamarckians pointed to various gaps within the fossil records as proof of their theory (Turney, Whitley, & Anderson, 1996). These gaps are now linked to punctuated equilibria, which is the theory that species tend to become stable in their evolution, stay largely the same for long stretches of time (otherwise known as stasis), and only evolve at specific instances to survive drastic changes to their environment (Eldredge & Gould, 1972).
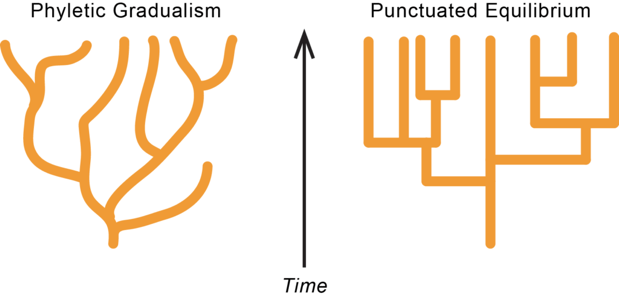
Fig. 1 Diagram to show comparison between Phyletic Gradualism and Punctuated Equilibrium (Kodazaje, n.d.).
Lamarck’s theory was accepted as a plausible formula until August Weismann countered it. (Turney, Whitley, & Anderson, 1996). Weismann (1893) showed that there are two kinds of cells in complex organisms. The first kind are germ cells that convey genetic information to the next generation’s young, and somatic cells that are not directly involved in reproduction. He argued that somatic cells could not possibly transfer any information which they acquired to germ cells, thereby ending the debate between Lamarckians and Darwinians (Weismann, 1893).
James Mark Baldwin (1896) proposed “a new factor in evolution”, through which similar characteristics could be passed down indirectly and manifest in the offspring. This “new factor” referred to phenotypic plasticity: a creature’s capability to change in response to environmental factors within its lifespan (Baldwin, 1896). The most straightforward and recognisable instance of phenotypic plasticity is learning, but other examples include getting tanner skin when exposed to excessive sunlight, forming calluses and scar tissue over external injuries, or building muscle mass through frequent exercise. (Turney, Whitley, & Anderson, 1996). Baldwin (1896) mentioned that this new factor could account for punctuated equilibria.
There are two main steps to the Baldwin effect. Firstly, it may begin with a partially successful mutation, which by itself is of no use to the organism. Phenotypic plasticity allows the organism to adapt beyond the scope of its mutation, allowing that partial mutation to work. If the fitness of the creature is improved by that mutation, it will multiply in abundance within that organism’s population. That being said, such adaptability is a burden on the individual, as time and energy is required for learning, and even so, with this slightly random element in play, mistakes might still occur. Thus, this second step is also recognised as part of the Baldwin effect: evolution may eventually replace the plastic mechanism with a more rigid mechanism so that an initial learned behaviour might eventually become instinctual.
1.3.3 The study of language as a complex system
Language can be identified as a complex adaptive system (CAS) (Gong, 2009). A CAS can be understood as a very complex system where changes in the nature of some factors as well as their interactions can bring about higher order dynamics. This system is made up of a large number of factors arranged in a hierarchical structure which changes according to its environment. As such, language then is a CAS as it is similarly complex in nature and has an adaptive ability. Computational simulation, with its bottom-up approach, is an appropriate tool to study language as a CAS as it allows researchers to build simulation models based on several pre-determined factors and linguistic environments to observe how the interaction of these factors, as well as the interaction between the environment and linguistic factors could affect language evolution (Cangelosi & Parisi, 2002).
1.3.4 Fluid Construction Grammar (FCG)
Languages work by the concept of “form and function pairings”. That is, the relationship between a word and its meaning is arbitrary; words have their meanings by virtue of us assigning such meanings to them. Hence, a word can take on a different meaning in different situations. One common example is as follows: the word form bank can mean the shore of a river and it can also mean the financial institution in which humans deposit their money for saving. Such meanings are also influenced by other aspects of language such as syntax, phonology, intonation and pragmatics. For example, if the word bank were to be stressed in conversation along with a rising tone, one could convey incredulity at a situation. In other words, the form of a word is essentially a sign packaged up as necessary for various purposes (Schneider & Tsarfaty, 2013).
Construction grammar is a formalised term for language models which represent all pairings of form and function as constructions in themselves, and adhere to the rules laid down by other language aspects. Four types of models exist: (1) full-entry model; (2) usage-based model; (3) default inheritance model and (4) complete inheritance model. However, the details of these models are not the focus of this chapter.
Currently there are several recognised construction grammar formalisms and amongst these there are two commonly known ones: Fluid Construction Grammar and Sign-Based Construction Grammar. The former takes the view of language being a working process between cognition and function (worldviews and mental methods of breaking down language structure) while the latter approaches language with a generative notion i.e. classifying whether sentence utterances are accepted as appropriate based on comparisons with descriptions of structures. Fluid Construction Grammar was conceived by Luc Steels (Bergen, 2008) and Sign-Based Construction Grammar by Ivan Sag and Hans Boas (Boas & Sag, 2012). Due to resource constraints we will focus only on Fluid Construction Grammar in this wiki chapter.
1.4 Studies involving the Baldwin effect
1.4.1 Language evolution and the Baldwin effect
Language’s principle usage is to transmit information. If we try to apply the principle of natural selection to account for the evolution of language faculty, an individual with the ability to produce grammatical morphemes should have a higher fitness. However, in practice, the individual alone would have no use for such a mutation, without a fellow individual with a similar mutation to communicate with (Geschwind, 1980). Hence, this shows the decreased likelihood of natural selection being the sole factor responsible for language evolution, and the increased plausibility that the ability to adapt and learn through the Baldwin effect was also crucial to the process (Watanabe, Suzuki, & Arita, 2008).
Watanabe, Suzuki, and Arita (2008) conducted an experimental study observing the Baldwin Effect in virtual agents by using a computational model. In their paper, they investigate the interaction between two adaptation processes: language learning and language evolution, across different time scales. For this purpose, they adapted the “speaker-hearer model” as described by Batali (1998), in a framework which combines cultural learning and genetic evolution, and “Adopted Cultural Learning” proposed by Kirby and Hurford (2002), an elaborated form of Iterated Learning.

Fig. 1 Overview of Model (Watanabe et al., 2008).
As seen in Figures 1 and 2, their model features two types of communication: Vertical communication from adult to child (unidirectional) and horizontal communication between two adults (bidirectional).
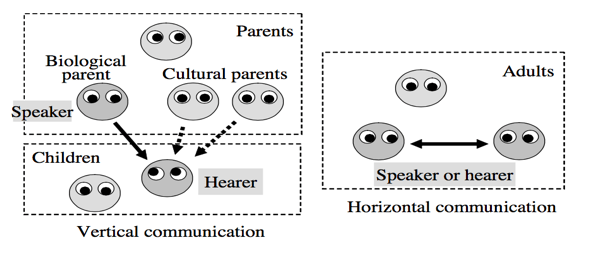
Fig. 2 Two Types of Communication (Watanabe, et al., 2008).
Process:
The child agent learns to make sense of what its biological and (randomly chosen) cultural parents are saying to it.
The child agent becomes an adult and takes turns talking and listening to a fellow adult agent of its generation.
The next generation is created from the fittest adults (determined by their communicative accuracy in (1) and (2)).
Each parent (biological and cultural) talks to its corresponding child agent.

Fig. 3 A Communicative Episode (Watanabe et al., 2008).
This process was repeated for 140 generations. To account for the second step in the Baldwin effect, the value of the agents’ plasticity was decreased over time.
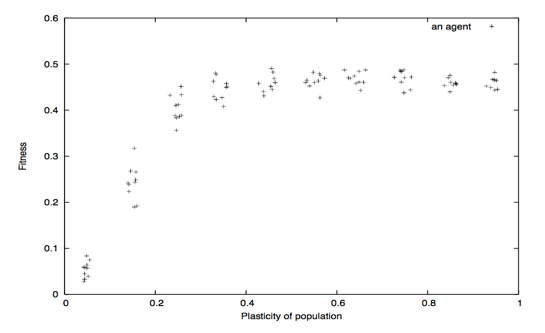
Fig. 4 Correlation diagram of fitness and plasticity of population (Watanabe et al., 2008).
As shown in Figure 4, the fitness of the individual showed a generally positive correlation with the population’s plasticity levels. However, this was only true up to a certain value of plasticity, approximately 0.4, beyond which there was no discernible improvement in fitness.
1.5 Studies involving Fluid Construction Grammar (FCG)
As an example, Gong, Minett and Wang (2010) studied the role of cultural transmission in language evolution. The computational simulation model used in the study simulated realistic language learning mechanisms in individuals. The model incorporated competition mechanisms, where some words are easier to learn and remember than others, as well as forgetting mechanisms, which simulate how individuals may forget the rules of a language while in the early stages of learning the language. These mechanisms enhance the degree of reality of the computational simulation model.
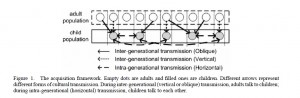
The figure above shows the language acquisition framework adopted in the study. It models three different forms of cultural transmission: (a) horizontal transmission where members of the same generation communicate with one another, (b) vertical transmission where members of an older generation communicate with those of a biologically-related younger generation and (c) oblique transmission where members of an older generation and members of a non-biologically related younger generation communicate with one another.
The results of the study show that language can develop and be maintained in a community when there are sufficient inter- and intra-generational transmissions.
In another study, Yamauchi and Hashimoto (2010) investigated the influence of niche construction on language evolution through a genetic-algorithm-based computational simulation model. Niche construction is understood to be a process where the activities of individuals lead to a change in their environment.
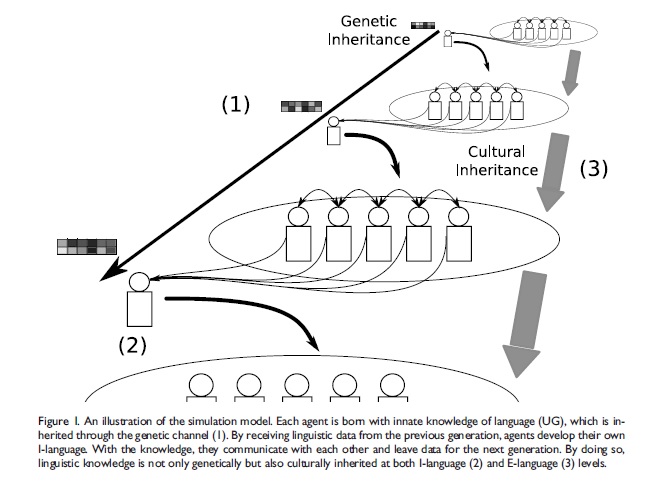
The figure above gives an illustration of the model. Individuals are born with universal grammar, an innate knowledge of language, which is inherited from the previous generation. The grammar of a language is then inherited via learning and is defined as I-language while the environment in which language learning and communication between individuals take place is called the E-language. The sociolinguistic environment is considered a niche-constructed environment as it is shaped by the linguistic innovations which take place during the evolution of a population.
The results show that natural selection favours individuals who are more adept at learning a language. Over time, as the population grows and evolves, a niche-constructed sociolinguistic environment in which individuals are adept at learning language is established. This leads to a decrease in the cost of language learning as genetic predisposition no longer plays as important a role in the acquisition of language. The importance of genes on language acquisition is then lessened over time.
1.5.1 Theory of FCG
FCG is an open-source software that enables linguists to play around with an inventory of construction grammar in order to test out theories and experiments related to the studies of language learning and evolution. To simply explain the flow: grammarians hypothesise or theorise how a language’s grammar could probably work, insert an inventory of words into the software, and then let the software compute the outcome of their theory. This computation is achieved through the use of templates (of grammar theories). For example, say a researcher theorised that the English language follows the syntactic structure of Subject-Verb-Object (object). An example sentence would flow like so: “John (subject) kicked (verb) the ball (object)”.
How then could the researcher test and verify if this theory is plausible? He or she would then create a template (through the software) of how the theory would work, insert an inventory of words that can be real or made up, then let the software run through all possible construction combinations until the last option is exhausted. The whole process is called a “transient structure”, where constructions are executed in a systematic fashion up to a point where nothing further can be worked out (Schneider & Tsarfaty, 2013). It works somewhat like how engineers, scientists, historians or similar researchers utilise predictive software to predict the possible outcomes of something they plan to do, or reverse engineer to find out how something came to be.
In a nutshell, Fluid Construction Grammar is basically application of artificial intelligence to construction grammar (van Trijp, 2013). It has grown from strength to strength, drawing from many fields of linguistics as research grows more sophisticated over the years, to become the FCG we use today. Steels eventually discovered that language is itself a master of acclimatisation, able to adjust accordingly in real time to interaction between interlocutors, instead of a fixed communication system that interlocutors adhere to as advocated by Chomsky (Van Trijp, 2013).
1.5.1.1 Design Patterns in FCG
There are certain design aspects of FCG worth noting, as introduced by Schneider & Tsarfaty (2013).
Firstly, some of the winning factors and selling points of FCG is that the scaffold of its system is sturdy and smoothly flexible. It was designed to be a schema for descriptive linguistic study hoping to investigate and educate on language change and progression.
Also, the software uses templates so that the researcher does not have to code or create anything from scratch – they just have to choose their parameters offered from the software.
According to Luc Steels, the creator of FCG, the flow of processing moves from lower-level linguistic units to higher-level phrasal units. That is, the software would first deal with simple combinations consisting of articles and single words (for example, the dog) and exhaust all iterations before moving to creating constructions in phrases (for example, the huge fluffy dog). Initial constructions come together to make up default ordered grammatical structures before supplementary constructions enforce further limitations that influence yet more resulting structure possibilities.
Next comes the more detailed workings of FCG – that which concerns the matching of elements between semantic and syntactic constituents; certainly no easy feat since each world language has its own systems of matching and producing these instances. The way FCG navigates through this huge pool of possibilities is by not limiting any default outcome at all – every lexical item can be assigned any potential constituent. It is only when constructions are applied that matches are made, in order to produce resulting phrasal structures. In other words, if we were to take the example sentence provided earlier (“John kicked the ball”) it is completely valid to also create a sentence which flows like “John kicked the kitchen” or like “Kitchen balled the John” and so on. Words that are traditionally verbs could take on the role of a subject or noun, and vice versa. Whether the semantic meaning makes sense does not matter at this stage; researchers would analyse and deduce conclusions after every possible construction has been formed. This method hence juxtaposes with the traditional generative grammar approach which often prescribes all constituent matches from the starting point. The resulting advantage that
FCG can boast over generative grammar is thus its facility to compute many more new constructions in languages/words it had yet been introduced to and deliver more instances of manipulation of constructions.
One more aspect worth noting is that despite the default setting described early of open and unrestrained application of constructions, FCG also allows for pre-set templates. These templates are also a demonstration of the frequencies of certain constructions. This is made possible through scoring of constructions ranging from favourable to common. That is, the software scores the tendency of certain templates being used. This allows an overall macro look at whether there are emerging patterns of certain grammatical constructions being preferred and help to improve efficiency in choosing templates for computation.
1.5.1.2 Application: FCG Case Study (Spanish L2)
There has been an FCG case study conducted on L2 Spanish verb morphology where the software was investigated/measured for accuracy, operationally defined as “the percentage of corrected forms that equals the human correction” (Beuls, 2014, p. 14). That is, the researchers would test and see what FCG offers up as the correct answer for verb conjugations, and compare those results with what a human L1 Spanish speaker will correct the answer with. In summary, FCG scored a 58% average on the complete sub-corpus, further broken down into 52% accuracy against low-intermediate level lexical items and 63% accuracy against the advanced lexical items. The research also suggested that FCG performed better with the mistakes of advanced Spanish L2 learners. When refined for enhanced accuracy i.e. corrections made by FCG on isolated lexical forms the software improved slightly to a score of 70% accuracy and the discrepancy between the two learning levels vanished.
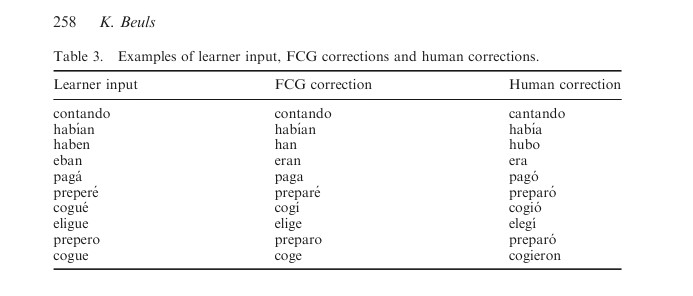
Figure 1
For further credibility they then compared the accuracy of the FCG’s results with what a word processing software would answer to see how similar they are in assessing the correctness of human grammatical constructions. The FCG’s performance was pit against the Microsoft Word spellcheck wherein the latter scored 30%, significantly lower than the FCG. This implies that the FCG’s reliability to compute constructions naturally (that is, in a humanistic way) is relatively credible and hence a tool worth considering for large scale language evolution studies.

Figure 2
1.6 Limitations of computational models
While computational simulation offers many benefits to the study of language evolution, it also has its limitations and difficulties. The two main limitations, simplification and specification, will be discussed below.
1.6.1 Considerations for design simplicity
Most computational simulation models are simplified to allow for an easier understanding of complex phenomena. However, this means that only certain features of language are incorporated into the models and as such they might not fully represent the actual processes in language evolution (Gong, 2009). Furthermore, humans, are biologically complex creatures with just as complex social behaviors (Loreto; 2010). The complexity of the mechanisms in these models pale in comparison to actual activities in human brains and attempts to increase their complexity could lead to them crashing (Cangelosi & Parisi, 2002). It should also be noted, that simplicity may not necessarily be a disadvantage of agent-based modelling. In simpler models, the outcomes of the model directly relate to the assumptions that we have modelled into it. This potentially helps us understand real-world data better (Smith, 2012). Conversely, realistic (i.e. more complex) models could lead to difficulty in discerning the effect that each factor has on the results (Gong, 2009). Relatedly, this consideration gives rise to a problem of selecting the factors that need to be input into the model. The next section explains this in further detail.
1.6.2 Considerations for design specifications
As seen in the simplification problem and in Part 1.2.1, we face a specification problem when modelling an agent. Specification is deciding what factors to include in a model. Simulation models are built to focus on certain factors which are relevant to the theory or hypothesis being studied. As mentioned above, language (and humans) are complex with various factors influencing each other and it is impossible to point to a single factor which can provide a full picture of language (Gong, 2009). While it would be ideal to build a model incorporating all possible factors which can influence language evolution, such a situation is not feasible as it would lead to the model becoming too complex to be studied (Gong, 2009). Thus, researchers have to specify the factors to be incorporated into a model and at the same time ensure that the model is not so simplified that it would generate results of little significance.
In short, the difficulty of computational simulation lies in building models that are sophisticated enough to explain language evolutionary processes while at the same time simple enough to be understood.