Linguistic complexity is a complicated aspect in Linguistics. Till now, scholars have been unable to give this term a proper definition.
The term complexity in linguistics has been used to refer to aspects of a language that make communication easier or simpler when speaking or to describe features of linguistic production (Palloti, 2014).
In other cases, some scholars claim that defining linguistic complexity is difficult due to the nature of the subject that demands it can only be defined when considering from whose perspective the complexity of a language is to be studied.
As a result of the difficulty in defining linguistic complexity, this wikichapter will instead aim to introduce the various models proposed with which one can study and begin to understand the concept of linguistic complexity.
The models described in this section are based on models lectured on by Osten Dahl, Stockholm Univeristy. Due to the problems with defining linguistic complexity above, linguists have yet to arrive at a distinct model. The particular one that will be elaborated on below has been selected based on the way it accounted for the multi-faceted nature of this topic. [Back to Table of Contents]
2.1 Objective Complexity VS Agent – Related Complexity
2.1.1 Objective Complexity
Objective complexity views complexity as an objective property of something. As if to say that complexity is characteristic of the object. This view is most common in information theory and when dealing with systems. In this view, it is hard to strictly define what complexity really is. [Back to Table of Contents]
2.1.1.1 System Complexity
System complexity is useful in linguistics when discussing language systems as a whole.
For example, when comparing the French language system with the English Language system, in terms of the use of articles, French is more complex.
In English, the article ‘an’ is placed before nouns beginning with a vowel and ‘a’ is used anywhere else. In French, ‘les’ is used before plural nouns, ‘la’ before feminine nouns, ‘l’’ before vowels and ‘le’ everywhere else.
In linguistics, system complexity would then help us in estimating how much, content wise, a person is required to learn to achieve proficiency in that language. But even here then, we can see a need to pick out specific aspects to judge complexity and that the system approach might not be as wholesome as it seems.
2.1.1.1 Structural Complexity
Structural complexity is useful in linguistics when we take on a more micro approach and aim to study the complexity of the structure of the language ie. utterances and sentences.
For example in studying the word order of languages. For example in English we use a Subject (S) – Verb (V) – Object (O) structure. Japanese on the other hand, uses SOV structure. The image below demonstrates what is meant by word order is various languages.
Here we see the debate that suggests linguistic complexity is dependent on from whose perspective it is being spoken about play out. From the perspective of a native English speaker, English or another SVO language such as Spanish, will be less complex than Japanese. For native Japanese speakers however, these would be seen as complex and other SOV languages like Persian, might be seen as less complex.
Agent related complexity is the view of looking at linguistic complexity from the person trying to use a particular language. There are several factors in assessing agent-related complexity; mainly cost, difficulty and verbosity.
2.1.2.1 Cost
Cost very simply refers to literally the cost of learning a new language such as time and money. Cost must also be seen in relation to benefit. This is very important in understanding agent related complexity.
For example, in Singapore, the cost of learning Italian may be high as it will require a lot of time and energy. The benefit is also low to the common man as they are unlikely to get much opportunity to actually speak Italian beyond the classroom. However, for a Singaporean student going on exchange to Italy or migrating there, the cost benefit is much higher and from their point of view the cost will seem lower. To the first person the value of time will be seen as high due to the low rewards but to the second, the value of time will be seen as less expensive. Hence cost as well is a very subjective verb and cost can range depending on what the person in question determines as important. If the person places more importance on time than money, and the language is easy to learn though it costs more, it will be seen as less complex to them. This again reflects the problematic subjective nature of the agent-related model.
2.1.2.2 Difficulty
Difficulty like complexity is hard to define as well as it largely depends on the individual’s perspective. One way of judging difficulty is by seeing if the attempts at learning a certain aspect of a language sees a larger number of failures than successes. This example is just one way of measuring difficulty. Difficulty like cost, seen above, and many other terms in the agent related model is extremely subjective and Dahl has not given a concrete definition to these. Thus it appears as these must be define in relation to the individual.
From a more purely linguistic point of view, we could also judge a language as more difficult if its language structure and system differ greatly from any of the languages that a person is native to or proficient in.
2.1.2.3 Verbosity
In his model, Dahl defines Verbosity as referring simply to the number of words required by a language’s grammar to convey a piece of information.
For example, in Tok Pisin ‘mi no harim tok bilong yu’ means ‘I do not understand’. In Spanish, it would be ‘no entiendo’. Here Tok Pisin is more verbose than English and people might then view Spanish as easier and less complex.
We have attempted to made our blog on this subject accessible to linguistic junkies as well as those not so linguistically-inclined. You can navigate our blog and learn more about Linguistic Complexity by navigating the menus. Do browse through the drop down sub-sections while you’re at it!
We hope you have a great time reading our blog and hope you learn more about Linguistic Complexity by the end of it!
Thank you,
Sathrin & Sabrina
1. Introduction
“….For it is a very remarkable thing that there are no men, not even the insane, so dull and stupid that they cannot put words together in a manner to convey their thoughts.”.Descartes, 1637/1960, p. 42
Descartes has in his quote stressed to us the intrinsic nature of language in the lives of humans. However Descartes oversimplifies language as upon reading the quote one gets the sense that language itself is easy to acquire given how anyone and almost every one acquires it to the point they are able to voice their thoughts. This firstly reduces the importance of the complex process of evolution that has been taking place for millions of years to enable humans to reach the point where we could begin producing speech. Secondly, the quote also demeans language by making it seem like something so easy to acquire. Here is where Descartes begins to get us to think about language complexity. To what degree is language easy to acquire and that is why no matter what the mental state of a man is, he can speak? And secondly thinking if this quote would apply to all societies and not just the Greek society of Descartes makes us question if this was not the case in other societies it is because there are languages that are more complex than each other?
Information about the first question can be found in areas of linguistics that handle language acquisition and child language. in this wikichapter our focus will be on the second question.
There are at present around 7,106 languages spoken in the world, non- uniformly distributed and linguistically divergent. These languages differ from each other substantially in form and structure (Joos 1957, P: 96). According to Hockett (1958. P:180-81), all the languages in the world have an equally complex job. So what ‘all languages are equally complex’ mean? Is it a logical deduction, or is there any quantifiable measurement of complexity.
There is no universally acknowledged and theory independent definition of language complexity (Steger and Schneider, 2012). Jeff Siegel (2004) points out that researchers disagree on whether language simplicity be judged absolutely, i.e. by some independent measure, or only comparatively, i.e. by comparison to another variety. It is also unclear if variety can be classified in terms of holistic simplicity or modular simplicity. It remains still controversial whether the language complexity should be understood quantitatively, i.e. in structural terms, or qualitatively, i.e. in psycholinguistic terms.
It is the controversial nature of this topic that will shape this wikichapter. This chapter does not aim to give answers to language complexity but rather hopes to help an understanding of it by focusing instead on various models that have been introduced in attempt to structure the attitudes and approaches that have been taken so far toward language complexity.
3.1 Using the phylogenetic method to study language evolution
3.1.1 How can phylogenetic methods be used to study language evolution?
Quantitative methods of studying language evolution requires data collection and comparison, similar to biological study of human evolution. While the study of human evolution requires comparison of physical or genetic characteristics of biological species, language evolution requires the study of linguistic data.
The concept of comparing lexical cognates in order to measure the distance between languages seem to have came from the French explorer Dumont D’Urville (Petroni & Serva, 2011). In D’Urville 1832 (cited in Petroni & Serva, 2011: 54), the French explorer used 115 lexical items and then assigned cognates a distance from 0 to 1. This list included all but three items that is in the 100-word Swadesh list that is widely used today to generate lexical distances between languages. The percentage of shared cognates between languages can be computed based on the Swadesh list in order to find out the distances between the languages of interest. Such wordlists can be used to build phylogenetic trees.
Phylogenetic analysis is based on a data matrix where the rows represent the languages to be studied and the columns represent a linguistic feature or character (Nichols & Warnow, 2008). Different languages may have different forms of a character and these are called ‘states’ of the character (Barbancon et al., 2013). There are three types of linguistic characters: lexical, phonological and morphological. For lexical characters, states correspond to cognate classes. When two or more languages are found to contain cognates, they will then be assigned the same character state.
Fig. 5. Cognate classes across English, French, Russian and Ingush
(Nichols & Warnow, 2008: 765)
In Fig. 5., sun, soleil and solnce are cognates, hence they are assigned the same state, (1). Maalx is not a cognate, hence it is assigned a different state, (2).
Fig. 6. Data matrix for linguistic phylogenetic analysis
(Pagel, 2009: 405)
Data matrix M in Fig. 6. is an example of an input to phylogenetic analysis. The first column of M represents a meaning which has four distinct states or cognate classes of words (0, 1, 2 and 3), whereas the second column denotes a meaning which only have two distinct states or cognate classes (0 and 1), and so on.
For phonological characters, states represent the presence or absence of certain sound changes in the history of the language; thus phonological characters may only have two states. Morphological characters, like lexical characters, have states that correspond to cognate classes, but instead of lexicon, they represent inflectional markers. The assumption is that if two languages display the same state for the same character, they share a common ancestry. However, borrowing may result in what seems like shared inheritance but is in fact a result of language contact. Parallel development and back-mutation, which are manifestations of a phenomenon called homoplasy, can also result in shared states that cannot be attributed to shared inheritance.
Many phylogeny reconstruction methods used to generate language trees are standard methods used in molecular phylogenetics.
Distance-based methods first transforms a character matrix into a distance matrix in which distances between the languages of interest are defined. A tree is then constructed based on the distance matrix (Nichols & Warnow, 2008). UPMGA (Unweighted Pair Group Method with Arithmetic Mean) is an algorithm that repeatedly joins two languages in the matrix that have the smallest distance. This method assumes that the dataset in the character matrix produce distances that evolves like clockwork, in another words obey the lexical clock. NJ (Neighbour Joining) joins pairs of languages that has the smallest corrected (that accounts for unseen state changes) distance and it does not need the clock assumption to hold (Barbancon, 2013).
Other methods include Maximum Parsimony (MP), Maximum Compatibility (MC) and Bayesian analyses (Nichols & Warnow, 2008). MP seeks a tree on which there is the least number of character state changes whereas MC seeks a tree on which there is a maximum number of compatible (evolved without homoplasy) characters. Bayesian methods estimates the probability of each tree being the true tree and produces a probability distribution of the group of trees. The Gray and Atkinson method is one of the bayesian methods used to construct language trees.
Also, unlike phonological comparison of linguistic data, whereby the sounds of words across languages are being compared, the resemblance-based model focuses on comparing words that appear similar morphologically in languages under the same family and across different language families. These words are known as cognate sets: words in different languages that are related semantically and morphologically (Dunn et al., 2005). With the reliance on cognate sets, this would help to lay out the greater linguistic family groups that are already known, such as Indo-European, Austronesian, Sino-Tibetan and etc. On top of that, these phylogenetic trees would allow researchers to detect possible relationships between languages which are not being detected previously by manual construction of phylogenetic trees by Historical linguists.
3.2.1 Studies that uses characters to construct phylogenetic trees
3.2.1.1 Language Phylogenies Reveal Expansion Pulses and Pauses in Pacific Settlement
Gray et al. (2009) investigated the origin and spread of the Austronesian language family by constructing a phylogeny of 400 Austronesian languages using lexical data and Bayesian methods. 210 lexical items including simple verbs, words for colors, numbers and animals from each of the languages were used. The origin of the Austronesian family was predicted to be in Taiwan approximately 5230 years before present. It was also revealed that the Austronesians spread through the Pacific in a series of expansion pulses and settlement pauses and this “pulse-pause” scenario is closely related with geographic expansions made possible by the availability of social and technological resources. The first pause may be attributed to the challenges in crossing the 350-km Bashi channel into the Philippines from Taiwan. The advancement in technology allowed the Austronesians to venture into new territories using new sailing modes, as seen in Pulse 1. The second pause was again, due to the difficulties in reaching far-flung islands of Eastern Polynesia. Later on, technological and social advancements have enabled the fourth pulse into Micronesia. The language phylogenies has enabled us to find many answers regarding cultural evolution and human prehistory.
Fig. 7. Phylogenetic tree of 400 Austronesian languages (Gray et al., 2009: 480)
3.2.2 Studies that uses phylogenetic trees to study language evolution
3.2.2.1 The Origin and Evolution of Word Order
Gell-mann and Ruhlen (2011) examined the word order of 2135 languages using a presumed phylogenetic tree of the world’s languages. They studied the distribution of the six word orders: SOV, SVO, VSO, VOS, OSV and OVS among the 2135 languages and found that the word order of the ancestral language is SOV. They suggested that most if not all of the modern languages derived from that very first SOV language and that those languages with the SOV word order simply preserved the original word order, except for languages which borrowed the word order from neighbouring languages. The large number of SOV languages today is not owing to the fact that this word order is “universally preferred” but simply because these languages inherited their word order from the ancestral language and have remain unchanged. The change in word order follows a particular pattern, that is it is almost always the case that SOV>SVO and SVO>VSO/VOS. Rare word orders like OSV and OVS may also have derived directly from SOV.
Fig. 8. The evolution of word order (Gell-mann & Ruhlen, 2011: 17291)
3.2.3.1 Automated Similarity Judgement Program (ASJP)
Automated Similarity Judgement Program (ASJP), is a programme under the resemblance-based method, that compares two languages at a time for lexical similarity. In this research by (Brown, Holman, Wichmann & Velupillai, 2007), ASJP database consists of 100-item list of core vocabulary from a number of distributed languages, depending on the sample used by researchers. This is known as Swadesh 100-item list of core vocabulary, in which a hundred glosses or meanings are used to be comparatively analysed. This is to establish when was the point whereby two related languages started to deviate from one another and separate into different branches. “Core vocabulary” would necessarily mean words for things that appear common in the environment of human beings such as body parts, colours, and natural objects such as sun, water, rain and etc (Brown, Holman, Wichmann & Velupillai, 2007).
There are 5 steps to ASJP. First and foremost, ASJP produces Lexical Similarity Percentage (LSP) for every pair of languages that are being compared. LSP is calculated by using a formula. ASJP would detect the number of items on the list (Swadesh 100-item list of core vocabulary) in which two compared languages have words that are phonologically similar. This number of items would then be divided by the number of meanings on list for which both of the languages have words for the particular vocabulary. Thereafter, the result would be multiplied by 100. Last but not least, LSP would be corrected for confounding factors and this results in Subtracted Similarity Percentage (SSP). SSP that is generated form a database to producing ASJP trees for languages.
A diagram of ASJP would look like the following:
1.1 100-item list
For this particular research, only a subset of 100-item list of (Swadesh, 1955) consisting of 40 most stable items are being used. The method for measuring stabilities is described in (Holman, Wichmann, Brown, Velupillai, Müller & Bakker, 2008).
Blood
Bone
Breast
Come
Die
Dog
Drink
Ear
Eye
Fire
Fish
Full
Hand
Hear
Horn
I
Knee
Leaf
Liver
Louse
Mountain
Name
New
Night
Nose
One
Path
Person
See
Skin
Star
Stone
Sun
Tongue
Tooth
Tree
Two
Water
We
You (sg)
1.2 ASJP Orthography
Languages around the world have different writing systems which might not be an effective way to compare vocabularies for lexical similarity. Therefore, there is a need to assemble words into a uniformed, standard orthography. With the help of International Phonetic Alphabet (IPA) symbols, the vocabulary items will be simplified. A unique feature of ASJP orthography is that it consists symbols found on QWERTY keyboard that is commonly used for English Language. The underlying reason behind this is that the ASJP symbols correspond with many sounds. It is constructed to represent all sounds that appear common to languages around the world. In some languages, there are sounds that are less common and are not precisely recognised in the orthography. Such rare sounds would then be identified by the ASJP symbol that is closest to the place and manner of articulation of those sounds. It is also worth to note that the ASJP procedure is not time consuming. Most of the processes, such as formulating a standardized orthography often takes less than an hour (Brown, Holman, Wichmann & Velupillai, 2007).
1.3 ASJP Formula
1.3.1 Lexical Similarity Percentage (LSP)
No. of items on 100-item list that are phonologically similar
No. of meanings on list in which both languages have words X 100
Figure 1. ASJP Tree for Indo-European Languages
(Brown, Holman, Wichmann & Velupillai, 2007).
Figure 1 illustrates the ASJP tree for certain Indo-European languages. It is imperative to note that the tree generated is not the full representation of the language families. This is due to the fact that only languages that are used in a particular research for comparative analysis will be reflected in the tree. It is evident that languages that are found on the same branch, such as German and English are more lexically similar as compared to those of different branches, such as German and Irish. Upon the construction of these trees, researchers could then compare the results produced by ASJP with the trees that are manually constructed by Historical linguists. In this particular example, there has been a mutual agreement among researchers as to the relationship found between languages found in Indo-European.
The accuracy of linguistic phylogenetic trees depends heavily on the properties of the data matrix (Pompei et al., 2011). The reliability of the data matrix in turn can be affected by rapidly mutating words, the varying rate of change of meanings and undetected borrowing. Words that mutate at a very rapid rates and meanings in a language that transform at differing rates can result in the disproportionality of language distance and evolutionary distance. Furthermore, undetected borrowing can look like shared ancestry but it is actually information flowing horizontally between languages. These factors may pose as confounds to language trees and researchers may fail to account for these factors if caution is not taken.
Even though the generation of data could provide us a correct simulated phylogenetic tree, it does, however, suffers from the fact that the true evolution remains unknown as it only provides us a probable scenario of how languages have evolved over the years. There is a limit to how far back in time we can trace the evolution of languages and this will pose as a striking limitation.
In addition, researchers tend to evaluate the methods on a language family that is most common to them, which may be a disadvantage for languages in other language families.
Atkinson, Q. D., & Gray, R. D. (2005). Curious Parallels and Curious Connections—Phylogenetic Thinking in Biology and Historical Linguistics. Systematic Biology, 54(4), 513-526.
Baldwin, J.M. (1896). A new factor in evolution. American Naturalist, 30, 441-451.
Barbançon, F., Evans, S. N., Nakhleh, L., Ringe, D., & Warnow, T. (2013). An experimental study comparing linguistic phylogenetic reconstruction methods. Diachronica, 30(2), 143-170.
Batali J (1998) Computational simulations of the emergence of grammar. Approach to the Evolution of Language, Cambridge University Press, Cambridge, pp 405–426
Bergen, B. K. (2008). A whole-systems approach to language: An interview with Luc Steels. Annual Review of Cognitive Linguistics, 6(1), 329-344.
Beuls, K. (2014). Grammatical error diagnosis in fluid construction grammar: a case study in L2 Spanish verb morphology. Computer Assisted Language Learning, 27(3), 246-260. doi: 10.1080/09588221.2012.724426
Boas, H. C., & Sag, I. A. (Eds.). (2012). Sign-based construction grammar. CSLI Publications/Center for the Study of Language and Information.
Cangelosi, A., & Parisi, D. (1998). The emergence of a ‘language’ in an evolving population of neural networks. Connection Science,10(2), 83-97.
Cartwright, D. (2006). Geolinguistic analysis in language policy. In T. Ricento (Ed.), An
introduction to language policy (pp. 194–209). Malden, MA: Wiley-Blackwell.
Dunn, M. (2005). Structural phylogenetics and the reconstruction of ancient language history. 309, 2072-2079. Retrieved from http://www.sciencemag.org/content/309/5743/2072
Eldredge, N., & Gould, S. J. (1972). Speciation and Punctuated Equilibria: An Alternative to Phyletic Gradualism [3rd draft]. American Museum of Natural History Research Library.
Everett C (2013) Evidence for Direct Geographic Influences on Linguistic Sounds: The Case of Ejectives. PLoS ONE 8(6): e65275.
Felix Richter (2013). Only 34% of All Tweets Are in English. [ONLINE] Available at: http://www.statista.com/statistics/267129/most-used-languages-on-twitter/. [Last Accessed 07 October 2014].
Geschwind N (1980) Some comments on the neurology of language. Caplan D (ed) Biological Studies of Mental Processes, MIT Press, Cambridge, MA
Gong, T. (2009). Computational simulation in evolutionary linguistics: a study on language emergence. Taipei, MA: Institute of Linguistics, Academia Sinica
Gong, T., Minett, J.W., Wang, W.S.-Y. (2010). A simulation study exploring the role of cultural transmission in language evolution. Connection Science, 22(1), 69-85.
Gell-Mann, M., & Ruhlen, M. (2011). The origin and evolution of word order. Proceedings of the National Academy of Sciences, 108(42), 17290-17295.
Gray, R. D., Drummond, A. J., & Greenhill, S. J. (2009). Language phylogenies reveal expansion pulses and pauses in Pacific settlement. Science, (5913), 479.
Hinton, G.E., and Nowlan, S.J. (1987). How learning can guide evolution. Complex Systems, 1, 495-502.
Holman, E. W., Wichmann, S., Brown, C. H., Velupillai, V., Müller, A., & Bakker, D. (2008). Explorations in automated language classification. 42(3/4), 331-354. Retrieved from http://eds.b.ebscohost.com.ezlibproxy1.ntu.edu.sg/eds/pdfviewer/pdfviewer?sid=d0458041-f6a8-4d03-9bd5-dbcce7acbd37@sessionmgr112&vid=0&hid=127
Kirby S, Hurford JR (2002) The emergence of linguistic structure: An overview of the iterated learning model. Cangelosi A, Parisi D (eds) Simulating the Evolution of Language, Springer Verlag, Berlin, pp 121–14
Kodazaje, T. (n.d.). [Digital image]. Retrieved from telirokodazaje.ultimedescente.com/phyletic-gradualism-1197411974.html
Loreto, V. (2010). Theoretical Tools in Modeling Communication. In S. Nolfi & M. Mirolli (Eds.), Evolution of communication and language in embodied agents (pp. 13-35). Berlin, Germany: Springer.
Mareschal, D., & Thomas, M. (2006). How computational models help explain the origins of reasoning. Ieee Computational Intelligence Magazine, 1(3), 32-40.
Munroe, S., & Cangelosi, A. (2002). Learning and the Evolution of Language: The Role of Cultural Variation and Learning Costs in the Baldwin Effect. Artificial Life, 8(4), 311-339.
Nallaperumal, K. & Krishnan, A. (2013) Engineering Research Methodology: A Computer Science and Engineering and Information and Communication Technologies Perspective. New Delhi, India: PHI Learning Private Limited.
Nichols, J., & Warnow, T. (2008). Tutorial on computational linguistic phylogeny. Language and Linguistics Compass, 2(5), 760-820.
Pagel, M. (2009). Human language as a culturally transmitted replicator. Nature Reviews Genetics, 10(6), 405-415.
Petroni, F., & Serva, M. (2011). Automated Word Stability and Language Phylogeny*. Journal Of Quantitative Linguistics, 18(1), 53-62.
Petzold T. (2010). Analysing Geo-linguistic Dynamics of the World Wide Web: The Use of Cartograms and Network Analysis to Understand Linguistic Development in Wikipedia.Internet Research Methods,3(2).
Pompei, S., Loreto, V., & Tria, F. (2011). On the accuracy of language trees. PloS one, 6(6), e20109.
Sigmund, K. (1995). Games of life: Explorations in ecology, evolution and behaviour. London: Penguin.
Smith, K. (2012). Why formal models are useful for evolutionary linguists. In M. Tallerman & K. R. Gibson (Eds.), The Oxford handbook of language evolution (pp. 581-588). New York, NY: Oxford University Press
Schneider, N., & Tsarfaty, R. (2013). Design patterns in fluid construction grammar. Computational Linguistics, 39(2), 447-453.
Swadesh, M. (1955). Towards greater accuracy in lexicostatistic dating. International Journal of American Linguistics, 21(2), 121-137. Retrieved from http://www.jstor.org.ezlibproxy1.ntu.edu.sg/stable/1263939?seq=1
Turney, P., Whitley, D., & Anderson, R. W. (1996). Evolution, Learning, and Instinct: 100 Years of the Baldwin Effect. Evolutionary Computation,4(3), Iv-Viii.
Twitter Visual insight manager (2013). The geography of Tweets. [ONLINE] Available at: https://blog.twitter.com/2013/the-geography-of-tweets. [Last Accessed 9 October 2014].
Van Trijp, R. (2013). A comparison between fluid construction grammar and sign-based construction grammar. Constructions and Frames, 5(1), 88-116. doi: 10.1075/CF.5.1.04VAN
Vogt, P. The emergence of compositional structures in perceptually grounded language games. Artificial Intelligence, 167(1-2), 206-242.
Watanabe, Y., Suzuki, R., & Arita, T. (2008). Language evolution and the Baldwin effect. Artificial Life and Robotics,12(1-2), 65-69.
Weismann, A. (1893). The Germ-Plasm: A Theory of Heredity. New York: Scribners.
White, T.D., Asfaw, B., Degusta, D., Gilbert, H., Richards, G.D., Suwa, G. & Howell, F.C. (2003). Pleistocene homo sapiens from Middle Awash, Ethiopia. Nature, 423, 742-747.
Wiley, E. O., & Lieberman, B. S. (2011). Phylogenetics [electronic resource] : theory and practice of phylogenetic systematics / [edited by] E.O. Wiley & Bruce S. Lieberman. Hoboken, N.J. : Wiley-Blackwell, 2011.
Yamauchi, H., Hashimoto, T. (2010). Relaxation of selection, niche construction, and the baldwin effect in language evolution. Artificial Life, 16, 271-287.
Yonathan Portilla, E. Altman”Geo-linguistic fingerprint and the evolution of languages in twitter” IEEE/ACM International Conference on Advances in Social Network Analysis and Mining 2012, pp. , doi:10.1109/asonam.2012.6570664
Phylogenetics, in biology, is concerned with the evolutionary relationships among biological organisms and it asserts that each species today is evolved from an ancestral species. A phylogenetic tree (Fig. 1.) is an illustration of the evolutionary history of various biological species through studying the similarities and differences in organisms (Wiley & Lieberman, 2011). Each line represents a lineage and the splitting of lineage as denoted by the node labeled “speciation event” results in two different species – sharks and osteichthyans. These two species shared a common ancestor denoted by the edge labeled “common ancestor” before the splitting of lineage happened.
Fig. 1. A biological phylogenetic tree
(Wiley & Lieberman, 2011: 5)
In linguistics too, it is assumed that languages today have evolved from ancestral languages that used to exist. There are many fundamental features that biological and linguistic evolution share (Fig. 2.).
Fig. 2. Features shared between biological and linguistic evolution
(Atkinson & Gray, 2005: 514)
The discrete characters in biological evolution, which are DNA sequences, like lexical characters, grammatical and phonological structures in languages, can be passed on from one generation to the next. Homologies in biological species, like cognates among languages indicate shared ancestry and inheritance from a unique ancestor. Cognates are words that show similar form and meaning, and can be shown to be inherited from a common ancestor through regular sound correspondences. Genes undergo changes through mutation and random drift, and so do linguistic characters. Lexical mutations can come in the form of innovation, such as the word boy, which appeared some time after English split from other west Germanic languages; as well as in the form of insertions, which happened to ‘books’ in Old Swedish which transformed from *bökr to böker, according to Campbell, 2004 (cited in Atkinson & Gray, 2005: 513). Linguistic diversification happens when lineages split forming two new languages and using this knowledge, we can reconstruct the historical relationships among languages by comparing linguistic features of languages.
Linguistic phylogenetic trees, such as in Fig. 3., represent the evolutionary history of a group of related languages (Nichols & Warnow, 2008). The common ancestor of all the daughter languages is represented by the root; the edges represents the intermediate ancestral languages; the nodes represent the splitting of language families into subfamilies; and the leaves represent the daughter languages.
Fig. 3. A phylogenetic tree
(Nichols & Warnow, 2008: 761)
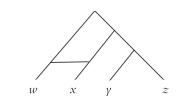
Estimated phylogenetic trees are not always binary trees (i.e. every internal node splits into two) because there may insufficient information to fully resolve the relationships between the subfamilies. Furthermore, a network model may be used for languages that have come in contact with each other resulting in phenomenons like borrowing, mixing and creolization to show additional edges indicating dual parentage (Fig. 4.).
Geo-linguistics is the study of language in relation to geography. Geo-linguistics is used to differentiate the areas where different varieties of the language are used. Geo linguistics has also been used to differentiate between the type of sounds found in the languages of different area. This new technology has allowed for easier linguistic research.
This new area of improvement in technology has been helpful to researchers and policy makers by helping to answer critical questions regarding language at International, national and urban levels (Cartwright, 2006). It has been helpful in media marketing as well. Knowing the different variations of languages spoken in different areas, advertisements could be created, catering to those varieties (Altman, Portilla, 2004).
2.1 Using Geo-linguistics to study about language evolution
2.1.1 Cartogram and Choropleth
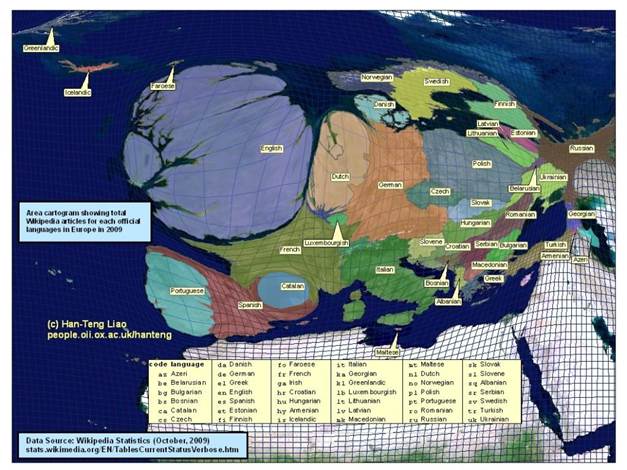
This particular study by Petzold has discovered that Wikipedia has more than 270 languages varieties. For example, Wikipedia provides different versions of Chinese which includes mainland Chinese, Singaporean and Malaysian version of simplified Chinese, Taiwan’s orthodox and Hong Kong’s traditional Chinese. Choropleth and Cartogram are used to ‘analyze if geographic and linguistic affinity has helped or hindered Wikipedia language versions to evolve’ (Petzold, 2011). The Choropleth acts as an indicator to show the linguistic development across the world. While the Cartogram shows the proportional size of a region to the population of the dataset (Petzold,2011). Follow up of these mappings for a few years will present the researchers with visible linguistic development in Wikipedia. Image 1 show an example of an Cartogram shows the total number of Wikipedia articles in Europe where English seems to be dominating.
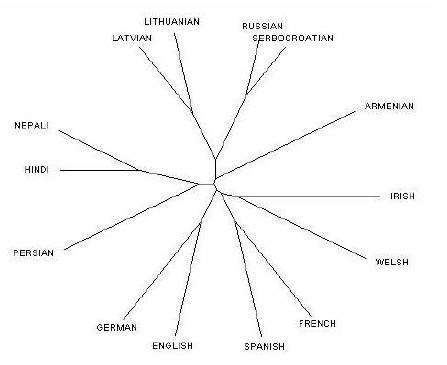
Network graphs represent the interconnection between languages. The language nearer to the centre of the network graph is considered to be the more universal language. Network graphs show a core-peripheral structure where researchers can analyse the extension of links among languages which restores, strengthens or changes the hierarchical relationships. Network graphs also work as a form of benchmark for the cartogram results analysis (Petzold, 2010). Image 2 is an example of a network graph of chosen language varieties of Wikipedia.
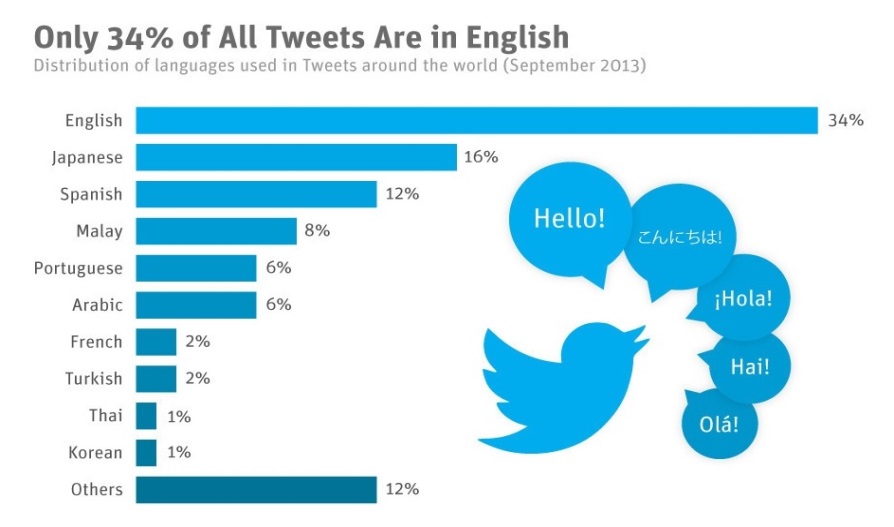
The idea of being able to tag your geographical location in social media may have been unthinkable decades ago. However, now it is a commonly used application. Researchers have been using these new available technologies to their advantage. Social media have knitted very close bonds with people. Their life is being updated on social media frequently. This would also mean that their language varieties and dialects are used to convey these updates to their followers. Table 1 below shows that only 36% of the language used in twitter is in English, while rest of the percentage is of other languages.
Table 1
With the help of Geo-twitter, researchers have been able to associate language varieties with certain regions. According to Statista (2013), a reputable statistics portal, English is in the top place with 36% of usage for the most famous language used in twitter. However, this statistics does not take into account the different varieties of English used in the various regions. With only 140 words available to bring across your message to the twitterverse, acronyms and shortened words have been formed.
A study by Altman and Portilla shows the analysis of evolution of words used in twitter. For example, the word ‘because’ has evolved into ‘cuz’, ‘coz’ and ‘cause’ according to the pronunciation of the people of the region. This analysis shows the different evolutions of the word in various geographical locations. The data of different varieties of the word used in twitter in different locations were collected through application program interface. Around 300 tweet samples with ‘because’ in it were collected for this analysis. The research has shown that the word ‘because’ has been clipped off the first syllable in most of the context such as ‘cuz’ and ‘coz’. These spellings differentiate the regional use as they are written as how they are pronounced with the different accents. ‘coz’ is prevalently used by the British English speakers while ‘cuz’ is mostly used by American English speakers. Even though less frequent, ‘cz’ was also used instead of the word ‘because’. However, the word ‘cs’ was never found to be used. Clipping of the word ‘because’ without removal of the first syllable was less common.
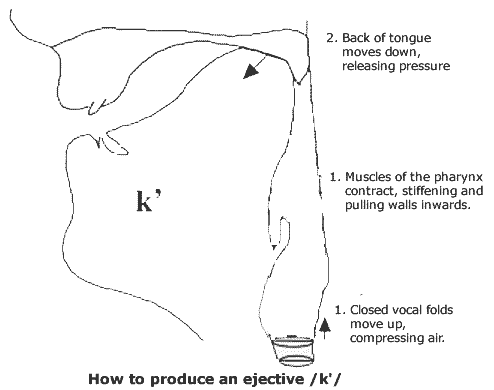
A recent study using the improved Geo-location technologies, Google earth and ArcGIS V. 10.0 has identified differences in the sounds of languages of different areas. This shows the language evolution to fit the environment of the language. The study had focused on the Ejective consonant sound. Ejective consonants found in twenty percent of the world’s languages have commonly been located in languages which are nearer to highly elevated areas as compared to languages without the ejective consonants. This phenomenon may be due to the lower air pressure in raised areas which lowers the effort needed to compress the air in the pharyngeal cavity (Everett,2013). This can be seen image below which shows that compression of air is needed in the process of producing ejective consonants. This also proposes that the languages in the high altitudes may have evolved to have ejective sounds as it is easier to produce in that geographical location.
(ArcGIS V. 10.0 is a geographic information system which acts as an geographic information database)
Fair analysis is not possible with automatic corrections. Many use twitter on their smartphones. Most smart phones provide automatic corrections. Some of these automatic corrections, do not identify the different varieties of English. Most smartphones or even computer automated corrector identify with American or British varieties of English. Hence, other varieties of English or the different sentence structures would get corrected leaving the data collector with a bunch of English language varieties similar to that of American or British.
In the Geo-twitter analysis, the clipped words tend to have meanings other than ‘because’. Hence might have been wrongly roped in. For example, ‘cos’ could also refer to the mathematical word, cosine and ‘cz’ could refer to Czech Republic in other contexts.
Tweets are short, and provide little context for analysis. Just like fingerprints, every individual would have slight tint of difference in their usage of language. Even when a group of people may be from the same region and may have grown up in the same kind of environment there might be differences in the usage of language. Twitter only allows 140 words for each post. Twitter users try to minimize their use of the words as well. This gives the data collector minimum context for analysis.
Not all parts of the country might have access to the internet nevertheless, twitter. The map below shows that twitter usage is concentrated in city areas as compared to rural areas of Europe. Therefore it might be difficult to get data of the different varieties of English spoken in different regions of the continent. The data collection might only be restricted to the regions with WiFi and where people have twitter. These regions usually tend to be the urban areas where more educated people live. The data from such a source would only be a reflection of the language variety spoken by the educated urban population. However, if this data collection process is done in perhaps 10 years’ time when technological development and knowledge of twitter has reached the rural population it would be considered a fair collection and analysis of data.
2.3.2 Limitations of the Geographical location study
There are outlier languages which are spoken in the elevated land but do not use ejectives (Everett C, 2013) . It is also difficult to measure the languages according to current geographical location. People speaking languages which were initially from the lower altitude areas may have moved to higher altitude areas during the different waves of migration and also due to globalization. A language might not only be spoken in one place but may be spoken in a few regions which have different geographical aspects. Thus reducing the credibility of this study.
Computational simulation has been used in various disciplines to study different natural phenomena and the use of this method has also been extended to the study of language evolution (Gong, 2009). Formal models have provided invaluable insight about the emergence of various phenomena such as the emergence of communication, categorizations of percepts, lexicon formation, and grammar formation. But what exactly is a formal model? It is a precise description of a system that is based on logic and mathematics to help us algorithmically and mechanically predict the system’s behavior from its description (Smith, 2012). There are concepts within this model (usually based on our assumptions) and the models prove properties of that concept (Nallaperumal & Annam, 2013). Thus, these systems produce replicable results. They are very precise and reliable, due to the use of equations which are essentially mathematical proofs. As we will see later, these computational models are built on sound assumptions and empirical findings (Gong, 2009; Smith, 2012). In addition, the ability of the models to incorporate a high degree of realism as well as the well-defined procedures involved in studies involving these models allow for convincing results which can be replicated. Results of studies involving computational simulation can hence be used to validate assumptions, hypotheses and theories.
Formal models are used to create autonomous computer programs (these are called “agents”), which are given special characteristics such as a physical body (i.e., they are “embodied”) and placed in certain environments. We observe how these embodied agents respond to situational changes and to other agents, and communication usually arises as a side effect of such an interaction. Examples of embodied agents include physical robots or simulated computer models. After the experiment is complete, statistics are drawn, interpreted and conclusions are drawn (Nallaperumal & Annam, 2013).
1.2 Advantages of using formal models in language evolution studies
1.2.1 Formal models test the validity of theories and hypotheses
Formal models complements traditional study methods by acting as a validity test for theories and hypotheses founded on limited empirical findings or unreliable assumptions. Our assumptions lead us to create verbal descriptions which may be robust in theory; however, more importantly, we want our assumptions to match up with real world data (Smith, 2012). By demonstrating how the theories and hypotheses work, formal models can help researchers to identify problems in the theories and to modify them (Gong, 2009; Smith, 2012). This is especially important for previous theories which are often vague and were difficult to test empirically (Gong, 2009). Moreover, the building of the simulation models also aids researchers in ensuring that their theories are detailed and complete (Cangelosi & Parisi, 2002) as any inconsistencies in the theories will cause the models to malfunction and crash (Mareschal & Thomas, 2006).
Designing a formal model to be programmed into an embodied agent requires working backwards. What does real-world data look like? How can we recreate these results in mathematical terms? Formal models thus compel us to reflect on the assumptions that we want to programme into our machine mind. These assumptions not only have to be grounded in empirical evidence, but the phenomenon that we are trying to investigate should also be well-understood (Smith, 2012). Due to the repeatability of formal models, we can results mean that of what assumptions are right, which should be modified, and which are wrong and should be discarded.
1.2.2 Formal modelling compels a rigorous definition of its components
Human language is a very complex system. As evolutionary linguists attempt to explain such a complex system, verbal theories become less reliable. This is because there is now a need to explore the consequences of a given set of assumptions, and this is where formal models come in useful (Smith, 2012). This is not to say that verbal theories should be discarded. They should work alongside formal models in the creation of embodied experiments. This can be explained by the fact that formal models require interpretation of results. It is not obvious what conclusions can be drawn from a simulation experiment at times. Hence, we need verbal definitions to help us move from numerical results towards making abstract generalizations about linguistic phenomena. These phenomena will necessarily hold true given the set of assumptions.
As mentioned by Karl Sigmund, the insight offered by a formal model could be more important than the predictions that it generates (Sigmund, 1995; Smith, 2012). While he was not entirely transparent about what this meant, we can extrapolate that manipulation of a formal model to programme it into a machine to fulfil a task, we gain a deep perception of the situation. We control such experiments by working with only one (or few) assumptions at a time. In evolutionary linguistics, dealing with multiple complex systems which interact to yield language can cause us to lose sight of the hidden processes in between. Formal models can help us elucidate some of these processes which are inherent in our assumptions. At the very least, if we fail to attain any insight of evolution from manipulating formal models, we gain insight about the structure and operation of the models themselves.
1.3 Studying language evolution through computational models
1.3.1 Modelling of various conditions and factors
Computational simulation models can be used to investigate the developmental process of language evolution. For example, studies on the emergence of language modelled different linguistic environments and had individuals programmed with some factors in order to examine whether these factors and environments could lead to the development of certain linguistic aspects (eg. Vogt 2005). This ability to manipulate various factors and conditions also allows researchers to make a comparison of results brought about by the different factors and determine which of these are necessary for the development of language. In addition, the effects of isolated factors as well as effects of sets of factors on language evolution can be studied. For example, a study done on the Baldwin Effects on the development of language isolated two factors, learning cost and cultural variation, and studied their separate effects on language (Munroe & Cangelosi, 2002).Section 1.3.2 provides an overview of the Baldwin effect as well as showing how this effect is programmed into an embodied experiment.
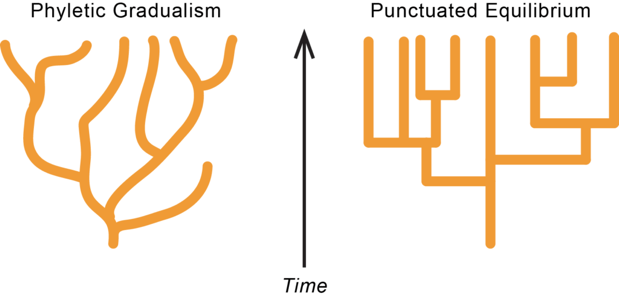
According to Turney, Whitley, and Anderson (1996), there were two opposing theories of evolution at the beginning of the 20th century, and it was not evident if Charles Darwin or Jean-Baptiste Lamarck explained evolution better. Lamarck believed any changes that happen to the parent could be passed right on to the offspring; while Darwin proposed that evolution could mostly be attributed to diversity and natural selection, where members of a species naturally varied from the mean by a slight margin, and only the fittest survived to pass on genetic information to the next generation (Turney, Whitley, & Anderson, 1996). A clearly identifiable distinction between the two theories was that Darwin’s supporters believed that evolution happened in small increments, in a process termed as phyletic gradualism, while Lamarck’s supporters believed that changes would occur sporadically and drastically (Turney, Whitley, & Anderson, 1996). Lamarckians pointed to various gaps within the fossil records as proof of their theory (Turney, Whitley, & Anderson, 1996). These gaps are now linked to punctuated equilibria, which is the theory that species tend to become stable in their evolution, stay largely the same for long stretches of time (otherwise known as stasis), and only evolve at specific instances to survive drastic changes to their environment (Eldredge & Gould, 1972).
Fig. 1 Diagram to show comparison between Phyletic Gradualism and Punctuated Equilibrium (Kodazaje, n.d.).
Lamarck’s theory was accepted as a plausible formula until August Weismann countered it. (Turney, Whitley, & Anderson, 1996). Weismann (1893) showed that there are two kinds of cells in complex organisms. The first kind are germ cells that convey genetic information to the next generation’s young, and somatic cells that are not directly involved in reproduction. He argued that somatic cells could not possibly transfer any information which they acquired to germ cells, thereby ending the debate between Lamarckians and Darwinians (Weismann, 1893).
James Mark Baldwin (1896) proposed “a new factor in evolution”, through which similar characteristics could be passed down indirectly and manifest in the offspring. This “new factor” referred to phenotypic plasticity: a creature’s capability to change in response to environmental factors within its lifespan (Baldwin, 1896). The most straightforward and recognisable instance of phenotypic plasticity is learning, but other examples include getting tanner skin when exposed to excessive sunlight, forming calluses and scar tissue over external injuries, or building muscle mass through frequent exercise. (Turney, Whitley, & Anderson, 1996). Baldwin (1896) mentioned that this new factor could account for punctuated equilibria.
There are two main steps to the Baldwin effect. Firstly, it may begin with a partially successful mutation, which by itself is of no use to the organism. Phenotypic plasticity allows the organism to adapt beyond the scope of its mutation, allowing that partial mutation to work. If the fitness of the creature is improved by that mutation, it will multiply in abundance within that organism’s population. That being said, such adaptability is a burden on the individual, as time and energy is required for learning, and even so, with this slightly random element in play, mistakes might still occur. Thus, this second step is also recognised as part of the Baldwin effect: evolution may eventually replace the plastic mechanism with a more rigid mechanism so that an initial learned behaviour might eventually become instinctual.
Language can be identified as a complex adaptive system (CAS) (Gong, 2009). A CAS can be understood as a very complex system where changes in the nature of some factors as well as their interactions can bring about higher order dynamics. This system is made up of a large number of factors arranged in a hierarchical structure which changes according to its environment. As such, language then is a CAS as it is similarly complex in nature and has an adaptive ability. Computational simulation, with its bottom-up approach, is an appropriate tool to study language as a CAS as it allows researchers to build simulation models based on several pre-determined factors and linguistic environments to observe how the interaction of these factors, as well as the interaction between the environment and linguistic factors could affect language evolution (Cangelosi & Parisi, 2002).
Languages work by the concept of “form and function pairings”. That is, the relationship between a word and its meaning is arbitrary; words have their meanings by virtue of us assigning such meanings to them. Hence, a word can take on a different meaning in different situations. One common example is as follows: the word form bank can mean the shore of a river and it can also mean the financial institution in which humans deposit their money for saving. Such meanings are also influenced by other aspects of language such as syntax, phonology, intonation and pragmatics. For example, if the word bank were to be stressed in conversation along with a rising tone, one could convey incredulity at a situation. In other words, the form of a word is essentially a sign packaged up as necessary for various purposes (Schneider & Tsarfaty, 2013).
Construction grammar is a formalised term for language models which represent all pairings of form and function as constructions in themselves, and adhere to the rules laid down by other language aspects. Four types of models exist: (1) full-entry model; (2) usage-based model; (3) default inheritance model and (4) complete inheritance model. However, the details of these models are not the focus of this chapter.
Currently there are several recognised construction grammar formalisms and amongst these there are two commonly known ones: Fluid Construction Grammar and Sign-Based Construction Grammar. The former takes the view of language being a working process between cognition and function (worldviews and mental methods of breaking down language structure) while the latter approaches language with a generative notion i.e. classifying whether sentence utterances are accepted as appropriate based on comparisons with descriptions of structures. Fluid Construction Grammar was conceived by Luc Steels (Bergen, 2008) and Sign-Based Construction Grammar by Ivan Sag and Hans Boas (Boas & Sag, 2012). Due to resource constraints we will focus only on Fluid Construction Grammar in this wiki chapter.
Language’s principle usage is to transmit information. If we try to apply the principle of natural selection to account for the evolution of language faculty, an individual with the ability to produce grammatical morphemes should have a higher fitness. However, in practice, the individual alone would have no use for such a mutation, without a fellow individual with a similar mutation to communicate with (Geschwind, 1980). Hence, this shows the decreased likelihood of natural selection being the sole factor responsible for language evolution, and the increased plausibility that the ability to adapt and learn through the Baldwin effect was also crucial to the process (Watanabe, Suzuki, & Arita, 2008).
Watanabe, Suzuki, and Arita (2008) conducted an experimental study observing the Baldwin Effect in virtual agents by using a computational model. In their paper, they investigate the interaction between two adaptation processes: language learning and language evolution, across different time scales. For this purpose, they adapted the “speaker-hearer model” as described by Batali (1998), in a framework which combines cultural learning and genetic evolution, and “Adopted Cultural Learning” proposed by Kirby and Hurford (2002), an elaborated form of Iterated Learning.
Fig. 1 Overview of Model (Watanabe et al., 2008).
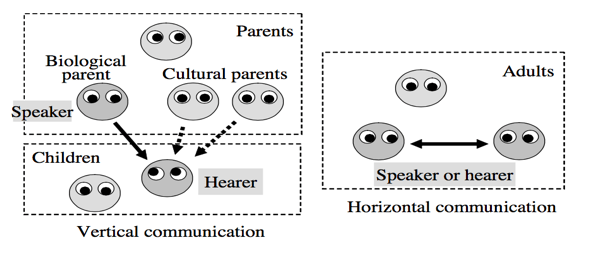
As seen in Figures 1 and 2, their model features two types of communication: Vertical communication from adult to child (unidirectional) and horizontal communication between two adults (bidirectional).
Fig. 2 Two Types of Communication (Watanabe, et al., 2008).
Process:
The child agent learns to make sense of what its biological and (randomly chosen) cultural parents are saying to it.
The child agent becomes an adult and takes turns talking and listening to a fellow adult agent of its generation.
The next generation is created from the fittest adults (determined by their communicative accuracy in (1) and (2)).
Each parent (biological and cultural) talks to its corresponding child agent.
Fig. 3 A Communicative Episode (Watanabe et al., 2008).
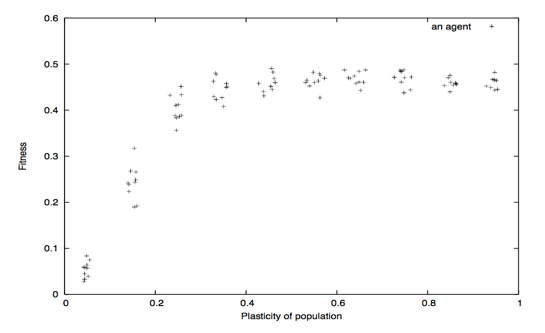
This process was repeated for 140 generations. To account for the second step in the Baldwin effect, the value of the agents’ plasticity was decreased over time.
Fig. 4 Correlation diagram of fitness and plasticity of population (Watanabe et al., 2008).
As shown in Figure 4, the fitness of the individual showed a generally positive correlation with the population’s plasticity levels. However, this was only true up to a certain value of plasticity, approximately 0.4, beyond which there was no discernible improvement in fitness.
1.5 Studies involving Fluid Construction Grammar (FCG)
As an example, Gong, Minett and Wang (2010) studied the role of cultural transmission in language evolution. The computational simulation model used in the study simulated realistic language learning mechanisms in individuals. The model incorporated competition mechanisms, where some words are easier to learn and remember than others, as well as forgetting mechanisms, which simulate how individuals may forget the rules of a language while in the early stages of learning the language. These mechanisms enhance the degree of reality of the computational simulation model.
A model of various forms of cultural transmission (from Gong et al., 2010: 76)
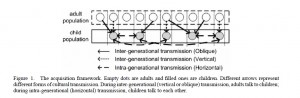
The figure above shows the language acquisition framework adopted in the study. It models three different forms of cultural transmission: (a) horizontal transmission where members of the same generation communicate with one another, (b) vertical transmission where members of an older generation communicate with those of a biologically-related younger generation and (c) oblique transmission where members of an older generation and members of a non-biologically related younger generation communicate with one another.
The results of the study show that language can develop and be maintained in a community when there are sufficient inter- and intra-generational transmissions.
In another study, Yamauchi and Hashimoto (2010) investigated the influence of niche construction on language evolution through a genetic-algorithm-based computational simulation model. Niche construction is understood to be a process where the activities of individuals lead to a change in their environment.
A model of the genetic and cultural inheritance of language (from Yamauchi & Hashimoto, 2010: 277)
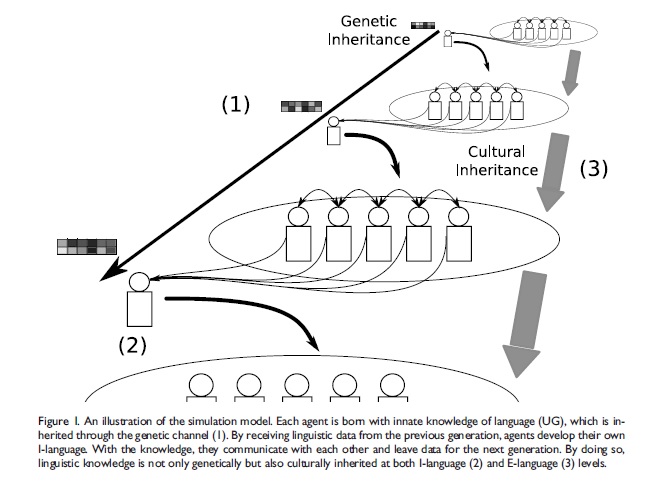
The figure above gives an illustration of the model. Individuals are born with universal grammar, an innate knowledge of language, which is inherited from the previous generation. The grammar of a language is then inherited via learning and is defined as I-language while the environment in which language learning and communication between individuals take place is called the E-language. The sociolinguistic environment is considered a niche-constructed environment as it is shaped by the linguistic innovations which take place during the evolution of a population.
The results show that natural selection favours individuals who are more adept at learning a language. Over time, as the population grows and evolves, a niche-constructed sociolinguistic environment in which individuals are adept at learning language is established. This leads to a decrease in the cost of language learning as genetic predisposition no longer plays as important a role in the acquisition of language. The importance of genes on language acquisition is then lessened over time.
FCG is an open-source software that enables linguists to play around with an inventory of construction grammar in order to test out theories and experiments related to the studies of language learning and evolution. To simply explain the flow: grammarians hypothesise or theorise how a language’s grammar could probably work, insert an inventory of words into the software, and then let the software compute the outcome of their theory. This computation is achieved through the use of templates (of grammar theories). For example, say a researcher theorised that the English language follows the syntactic structure of Subject-Verb-Object (object). An example sentence would flow like so: “John (subject) kicked (verb) the ball (object)”.
How then could the researcher test and verify if this theory is plausible? He or she would then create a template (through the software) of how the theory would work, insert an inventory of words that can be real or made up, then let the software run through all possible construction combinations until the last option is exhausted. The whole process is called a “transient structure”, where constructions are executed in a systematic fashion up to a point where nothing further can be worked out (Schneider & Tsarfaty, 2013). It works somewhat like how engineers, scientists, historians or similar researchers utilise predictive software to predict the possible outcomes of something they plan to do, or reverse engineer to find out how something came to be.
In a nutshell, Fluid Construction Grammar is basically application of artificial intelligence to construction grammar (van Trijp, 2013). It has grown from strength to strength, drawing from many fields of linguistics as research grows more sophisticated over the years, to become the FCG we use today. Steels eventually discovered that language is itself a master of acclimatisation, able to adjust accordingly in real time to interaction between interlocutors, instead of a fixed communication system that interlocutors adhere to as advocated by Chomsky (Van Trijp, 2013).
There are certain design aspects of FCG worth noting, as introduced by Schneider & Tsarfaty (2013).
Firstly, some of the winning factors and selling points of FCG is that the scaffold of its system is sturdy and smoothly flexible. It was designed to be a schema for descriptive linguistic study hoping to investigate and educate on language change and progression.
Also, the software uses templates so that the researcher does not have to code or create anything from scratch – they just have to choose their parameters offered from the software.
According to Luc Steels, the creator of FCG, the flow of processing moves from lower-level linguistic units to higher-level phrasal units. That is, the software would first deal with simple combinations consisting of articles and single words (for example, the dog) and exhaust all iterations before moving to creating constructions in phrases (for example, the huge fluffy dog). Initial constructions come together to make up default ordered grammatical structures before supplementary constructions enforce further limitations that influence yet more resulting structure possibilities.
Next comes the more detailed workings of FCG – that which concerns the matching of elements between semantic and syntactic constituents; certainly no easy feat since each world language has its own systems of matching and producing these instances. The way FCG navigates through this huge pool of possibilities is by not limiting any default outcome at all – every lexical item can be assigned any potential constituent. It is only when constructions are applied that matches are made, in order to produce resulting phrasal structures. In other words, if we were to take the example sentence provided earlier (“John kicked the ball”) it is completely valid to also create a sentence which flows like “John kicked the kitchen” or like “Kitchen balled the John” and so on. Words that are traditionally verbs could take on the role of a subject or noun, and vice versa. Whether the semantic meaning makes sense does not matter at this stage; researchers would analyse and deduce conclusions after every possible construction has been formed. This method hence juxtaposes with the traditional generative grammar approach which often prescribes all constituent matches from the starting point. The resulting advantage that
FCG can boast over generative grammar is thus its facility to compute many more new constructions in languages/words it had yet been introduced to and deliver more instances of manipulation of constructions.
One more aspect worth noting is that despite the default setting described early of open and unrestrained application of constructions, FCG also allows for pre-set templates. These templates are also a demonstration of the frequencies of certain constructions. This is made possible through scoring of constructions ranging from favourable to common. That is, the software scores the tendency of certain templates being used. This allows an overall macro look at whether there are emerging patterns of certain grammatical constructions being preferred and help to improve efficiency in choosing templates for computation.
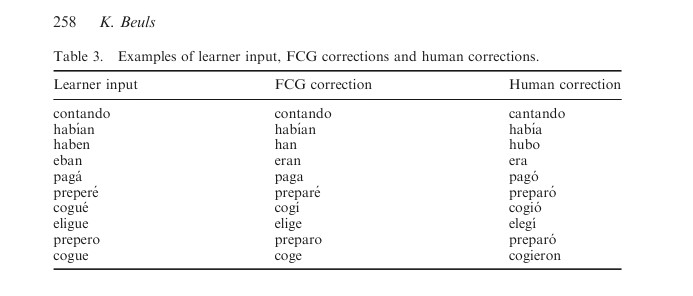
There has been an FCG case study conducted on L2 Spanish verb morphology where the software was investigated/measured for accuracy, operationally defined as “the percentage of corrected forms that equals the human correction” (Beuls, 2014, p. 14). That is, the researchers would test and see what FCG offers up as the correct answer for verb conjugations, and compare those results with what a human L1 Spanish speaker will correct the answer with. In summary, FCG scored a 58% average on the complete sub-corpus, further broken down into 52% accuracy against low-intermediate level lexical items and 63% accuracy against the advanced lexical items. The research also suggested that FCG performed better with the mistakes of advanced Spanish L2 learners. When refined for enhanced accuracy i.e. corrections made by FCG on isolated lexical forms the software improved slightly to a score of 70% accuracy and the discrepancy between the two learning levels vanished.
Figure 1
For further credibility they then compared the accuracy of the FCG’s results with what a word processing software would answer to see how similar they are in assessing the correctness of human grammatical constructions. The FCG’s performance was pit against the Microsoft Word spellcheck wherein the latter scored 30%, significantly lower than the FCG. This implies that the FCG’s reliability to compute constructions naturally (that is, in a humanistic way) is relatively credible and hence a tool worth considering for large scale language evolution studies.
While computational simulation offers many benefits to the study of language evolution, it also has its limitations and difficulties. The two main limitations, simplification and specification, will be discussed below.
Most computational simulation models are simplified to allow for an easier understanding of complex phenomena. However, this means that only certain features of language are incorporated into the models and as such they might not fully represent the actual processes in language evolution (Gong, 2009). Furthermore, humans, are biologically complex creatures with just as complex social behaviors (Loreto; 2010). The complexity of the mechanisms in these models pale in comparison to actual activities in human brains and attempts to increase their complexity could lead to them crashing (Cangelosi & Parisi, 2002). It should also be noted, that simplicity may not necessarily be a disadvantage of agent-based modelling. In simpler models, the outcomes of the model directly relate to the assumptions that we have modelled into it. This potentially helps us understand real-world data better (Smith, 2012). Conversely, realistic (i.e. more complex) models could lead to difficulty in discerning the effect that each factor has on the results (Gong, 2009). Relatedly, this consideration gives rise to a problem of selecting the factors that need to be input into the model. The next section explains this in further detail.
As seen in the simplification problem and in Part 1.2.1, we face a specification problem when modelling an agent. Specification is deciding what factors to include in a model. Simulation models are built to focus on certain factors which are relevant to the theory or hypothesis being studied. As mentioned above, language (and humans) are complex with various factors influencing each other and it is impossible to point to a single factor which can provide a full picture of language (Gong, 2009). While it would be ideal to build a model incorporating all possible factors which can influence language evolution, such a situation is not feasible as it would lead to the model becoming too complex to be studied (Gong, 2009). Thus, researchers have to specify the factors to be incorporated into a model and at the same time ensure that the model is not so simplified that it would generate results of little significance.
In short, the difficulty of computational simulation lies in building models that are sophisticated enough to explain language evolutionary processes while at the same time simple enough to be understood.
2019: Nur Amirah Bte Rosman, Joanne Tan Hui San, Cheng Wei Cong Jonathan
2015: Nur Eliqah Binte Mohd Ali, Nur Syazwani Binte Jantan
2014: Toh Xiao Xuan, Kenneth Su Weihao, A K Vellie Nila
Hello everyone!
Language evolution has traditionally been studied using methods such as the examination of fossil remains, comparisons between animal communication systems and studies of patients with language impairments (Gong, 2009). These methods of study have led to an increase in the understanding of the nature of language. For example, studies of the fossils of hominids have allowed researchers to date the emergence of anatomically modern humans to about 160,000 years ago (White, Asfaw, Degusta, Gilbert, Richards, Suwa & Howell, 2003). With technological improvements, researchers have now come up with several new quantitative methods which are complementary to the traditional methods of study and have the potential to further advance the current knowledge of language evolution. New methods also make use of expertise and knowledge from other fields of study such as computer science and biology, demonstrating that learning about the evolution of language does not necessarily have to be restricted to the field of linguistics. Three of these new methods, namely, computational simulation, Geo-linguistic and phylogenetic methods will be introduced in these pages.
Feel free to click on the links to understand these new quantitative methods to study language evolution!
2015: Muhammad Hairulnizam Bin Samsudin, Nur Atikah Ibrahim
2014: Charlotte Choo, Christian Teo Jocelyn Tong
Hello readers,
Welcome to our blog!
Here, we will be exploring the concept of the evolution of language through bio-cultural adaptation, and we will split our perspectives in three ways:
1) Language evolution through biological adaptation
2) Language evolution through cultural adaptation
3) Language evolution through both biological and cultural adaptation
You can find these information on the tabs above. We have also included a glossary for your reference, in case you need some clarification for the terms we have used in our discussion!
Happy reading!
1.1 About Us
Atikah, Nizam & Sarah-Grace says hi!
We are a group of linguistics students and we are really excited to be part of this project, which is going to provide an informative platform where people can learn more about the murky beginnings of language (and perhaps help shed more light about language’s history), as well as its growth since. [Back to Table of Contents]
2. Biological Evolution
Under this tab, we will explore the biological adaptations of language. It is divided into two categories namely:
1) Increase in Brain Size
2) Adaptationist Position
2.1 Increase in Brain Size
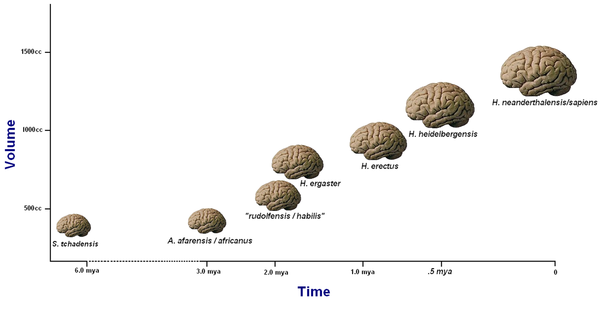
Brain size is believed to have tripled over the period of human evolution. Today, the human brain is known to be one of the largest and the most complex that has developed since early humans days. Brain size is said to have evolved concurrently with the increase in brain to body ratio. As mentioned under the cultural evolution tab, early humans had developed stone tools and such technological advancements together with new environmental challenges that primates faced in the past, tested humans’ fitness for survival. This led to the development of bigger bodies and thus bigger brain size and much more complex brains. As a result, presently, our brains are able to process and store more information due to its larger capacity, serving us a big advantage.
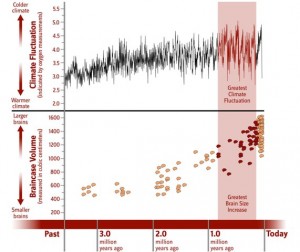
Figure 2 below illustrates how brain capacity or volume has increased over time with comparison to the climate fluctuation patterns. As seen within the red zone, during the period of great climate fluctuation, it has led to the greatest volume of brain size increase. Henceforth, this may provide the explanation as to how and when the human brain evolved significantly to how it is today (Brains, n.d.).
In addition, the development in brain capacity is further supported by the theory that primary tool making techniques and process of early humans has acted as a stimulus in the specific brain region specialised for manual manipulations and speech production. This improvement in technological aspect of early humans emerged during the period of the Homo Habilis. Over time, this resulted in a gradual increase in brain size as shown in the diagram below (Bolhuis et. al, 2014).
Timeline:
From 6 – 2 million years ago Slight increase in Brain Size Bipedalism, which is the way of walking upright started in early humans. It then resulted in the advancement of simple tool making. Thus, brain size increased slightly.
From 2 million – 800,000 years ago Increase in Brain to Body ratio This was the period where early humans began dispersing across continents. This led to the various encounters of new environments. With the process of natural selection, due to the challenges faced, the early humans experienced an increase in body size, which simultaneously resulted in bigger brains.
From 800,000 – 200,00 years ago Rapid increase in Brain Size The bio-climatic effects that occurred during this period has caused the human brains to evolve most significantly (Beals et. al, 1984). These environmental forces influenced the way early humans interact with their peers and surroundings thus resulted in a larger and more complex brains in order to cater to the needs of early humans. This proves to be an essential mean of survival which enabled our ancestors to last till today (Brain, n.d.).
2.2 Evolution of the Vocal Tract (Adaptationist Position)
Adaptationism refers to the view of natural selection being the main drive or cause to explain for any biological evolutionary (Forber & Orzack, 2012). Natural selection refers to the process where a heritable biological trait becomes more common or less common due to its advantage or disadvantage. What this means, is that a biological trait slowly become biologically innate in the genetics that is slowly changing through the future generations. (Natural Selection, n.d) One example would be the skin of a human foot. As humans evolved to walk more the skin of the ball of the foot becomes harder (to withstand pressure) over the next generations as natural selection occurs.
Similarly, natural selection takes place for communication and language to evolve. Earlier on, we have talked about the evolution of the brain and how it generates and stimulate the cognitive function to communicate; earliest forms being grunts and gestures (See section on Increase in Brain Size). This need to communicate led to those grunts and gestures to slowly evolve into more meaningful and effective way to communicate which is through voicing. This advantage would then lead to the evolution of the vocal tract.
Images from http://pubpages.unh.edu/~jel/images/vocal_tract_chimp.gif
From the above image we are able to see the difference of the vocal tract of the primates which our earlier ancestors share a similar tract with and the vocal tract of the human tract. The difference is the position of the larynx that consists of the vocal cords which is the instrument of producing sounds. The position of the larynx is while in the human larynx is higher resulting in a two-tube vocal tract that enable to voice more sounds as it goes beyond normal lung volume for normal breathing and this exquisite control of lung volume passing through attributes to long fluent sentences by human beings (Ghanzafar & Rendall, 2008). However, there is an advantage of having a high larynx position as apes are able to eat and breathe at the same time while normal human adults cannot as the lower larynx results in pathways to the lungs and stomach to intersect making the risk of choking higher. Nevertheless, natural selection dictates that having the ability to speak and communicate is more advantageous resulting in the biological evolution of the vocal tract and thus evolving language.
Another view called the exaptationist account offers a different explanation than natural selection. The explanation is that some biological trait or features were initially used for a specific reason but over the course of generation has evolved and co-opted to be used for other reasons too (Exaptation, n.d). MacNielage (2008) stated that a lot of the parts of the vocal systems were initially used for different specific parts but they evolve to work together in producing speech over the years.
Whatever views that one accounts for the evolution of the vocal tract, there is no doubt that the evolution of speech and language itself stemmed from the biological evolution of the vocal tract to be able to produce extensive amounts and varieties which would later on be used as a communication system.
Under this tab, we will explore the cultural adaptations of language. There will be three categories namely:
1) Invention of tools & devices
2) Creolisation
3) Development of Cultural Systems
3.1 Invention of Tools & Devices
One of the early human cultural developments include stone tool making. These tools are useful devices such as those for hunting or building houses. Language may have been ‘invented’ or evolved about the same time that tools were made (Stout & Chaminade, 2009). The advancement of language was largely due to this process of tool making since scientific research proved how the invention of tools stimulated the brain of the early humans thus developing cognitive ability leading to language (Balter, 2013). In addition, apart from stimulating the cognitive area of the brain (specifically the Broca’s area), stone tool making too encouraged the need for intercommunication since making tools require intercommunication in order to acquire the specialized skill. Culture was hence produced not only by man’s higher intellectual development but also by his increased social life. In other words, higher intellectual development of man and the development of superior means of intercommunication go hand in hand and form the foundation of culture for early humans (Ellwood, 1918; Dediu et. al, 2013).
Figure 1 below illustrates the development of the various stone tools, which showed the ‘jump’ in technological advancement and thus underlying cognitive skills (Snelling & Matthews, 2013).
Creoles too, played a vital part in the process of language evolution through cultural means. There are several views regarding the evolution of creole languages. Initially many viewed creole as having evolved from pidgins and is considered as a simplified language, which has been nativized by the second generation of pidgin speakers. Such creoles are said to have typically arose when these children transformed the pidgins “from proto-languages to full-fledged languages” (Mufwene, 2007). However, there exist a more recent opinion stating that creoles evolved from the setting of a social context where they developed from a necessity for communication between linguistic groups who are non-mutually intelligible amongst each other. This occurred especially during trade contacts during the 16th to 19th century between the European and non-Europeans (Mufwene, 2007).
Despite the difference in the idea of how creoles came about, the significant issue at hand is that creoles played a vital process in the evolution in language since the process of creolization was mainly driven by social interaction. Some examples of creole languages in practice include the Haitian Creole, which fused Standard French and the native languages of Haiti, and was known to have emerged due to the need for communication amongst the slave traders and their masters. Bonenfant (2011) further explained how it initially came about as a language contact and then developed as a lingua franca (Bonenfant, 2011). The creole language recently also gained English influences via contacts with American English. Thus, this addresses the phenomena of language contact which plays a vital part in cultural influences of linguistic development.
Another cultural progress in early humans that have had a huge impact on the evolution of language is the development of writing systems (Dediu et al., 2013). Prior to the invention of writing systems, humans could only communicate verbally, and hence had to keep their utterances short, simple and easy to understand. However, with the ability to record language, humans could begin to form increasingly complex sentences, both in terms of lexicon, morphology and syntax (Dediu et al., 2013).
The development of writing systems itself has also been seen as an evolutionary leap in language. It is seen as a significant milestone in the transition of early humans from barbarism to civilisation. In the earliest records of human language writing systems, iconic symbols or logos were used to represent various notions. However, numerous modern languages utilise symbols that speakers have agreed upon to represent ideas independent of their pronunciation. Some examples include the alphabetic and syllabic writing systems. To put it in other words, there was a crucial progression from concrete to abstract representation that gave rise to the arbitrariness of human language in the contemporary world.
Today, the development of such cultural systems include the advancement in information technology. As an example, we can see how the invention and prevalence of social media creates a new dimension for language use and evolution. For instance, new words and phrases such as LOL, which means laugh out loud, are coined and incorporated into our everyday language.
We will also be exploring the overlap of both biological and cultural evolution. This can be largely explained via the theory of child language acquisition.
4.1 Child Language Acquisition
One of the most distinct examples of language evolution is a child’s acquisition of language. Humans are able to acquire the ability to perceive, comprehend and communicate with words and sentences at a very young age. This seemingly innate ability is often argued as a biological evolution of the human language. A common basis that this argument made use of is Chomsky’s theory of Universal Grammar. It is a theory that accounts for how arbitrary properties and the complexity of language can be comprehended and reproduced to convey different infinite sets of meaning by a human child during language acquisition period. A child being able to use features of grammar that is not evident in his or her own first language shows that those features are encoded in the acquisition device. Hence, revealing that there must be a certain degree of structure in the language-specific capacity that has evolved that shapes nature of learning a language easily at a relatively young age. (Kirby & Smith, 2008)
However, some arguments question why the structure of language capacity in the brain is then structured that way and presented views of language adaptation through cultural transmissions. Language is acquired socially and through observations of linguistic behaviours of others (Kirby & Smith, 2008). Kirby and Smith also introduced the idea of iterated learning that further exhibit cultural transmission of language through imitation and learning from others. This accounts for biases from cultural experience (eg. The people they interact with) cause changes in a language during the acquisition period. Thus, explaining to a certain degree of how different language developed over the years.
Some researchers further classify the phenomenon of child language acquisition as both a cultural and biological evolution, linking it to the idea of natural selection where a characteristic that increases fitness would lead to individuals needing less exposure to develop it as it becomes biologically encoded ( Christiansen et al, 2011). Brighton, Kirby and Smith (2005) proposed a similar concept with regards to language changed called cultural selection. It suggests that language changes and adapt to increase the ease of learnability. Language first evolved for its functional advantage of communication. A child is then born with the ability to learn a language and comprehend sets of linguistic universals. Next, an individual acquire the language through cultural transmissions and interactions in the society which have also undergo changes. These acquired linguistic forms are then passed to the next generation and will only survive through constant application and its functionality. For example, learning vocabularies in language increases communicative abilities as such establishing the capability to map forms and meaning would gradually be innate as biological adaptation takes place. This illustrates cultural selection occurring through the biological adaptation of certain relevant forms to make it easier to learn and use a language(Christiansen et al, 2011).
Even though there are different perspectives of language acquisition in the evolution of language, it is evident that both cultural and biological changes played roles in language evolution.
Although language is no longer just used for basic needs for survival, the evolution of language continues as new generations integrate new technology as a part of their daily vocabulary. Just as stone tool making had also used communication to improve on technology across generations, our future generation will continue to evolve language to technology as our society becomes more heavily depended on it. Language just like biological evolution will continue to evolve to simplify tasks and getting meaning across to another person more effectively. As efficiency in communication grows, it will allow for more room in the brain to develop in different aspects of life, forcing humans to be able to achieve more. As we continue to study the capabilities of the brain to acquire language, use and its creative outlets, we can see that biological factors on a primitive level will still play a large role in language learning. On the other hand, it can be observed that a child’s language ability is not only depended on the natural capabilities of its brain but rather, its social environments could play a larger role in the amount of knowledge and languages a child could be exposed to. Therefore, the evolution of language cannot be just observed as solely biological or socio-cultural but rather the interworking of the two contributed to the development of human languages today.
Broca’s Area: Refers to a region of the brain concerned with the production of speech, located in the cortex of the dominant frontal lobe. Damage in this area causes Broca’s aphasia, characterised by hesitant and fragmented speech with little grammatical structure.
Natural Selection: The process of the survival of the fittest, where better adapted organisms are able to continue producing offsprings. This is a theory discovered and proposed by Charles Darwin and is being regarded as the main process bringing about evolution.
Patterned ideas: When the development of cultural evolution takes place and is used by groups. [For example, the making of stone implements a certain pattern and is followed until it is relatively perfected.]
Asif A. Ghazanfar & Drew Rendall(2008, June 3), Evolution of human vocal production, Current Biology, Volume 18, Issue 11
Balter, M. (2013, March 9). Striking Patterns: Study Suggests Tool Use and Language Evolved Together |WIRED. Retrieved March 23, 2015, from http://www.wired.com/2013/09/tools-and-language/
Beals, K., Smith, C., & Dodd, S. (1984). Brain Size, Cranial Morphology, Climate, and Time Machines. Current Anthropology,25(3), 301-330.
Bolhuis, J., Tattersall, I., Chomsky, N., & Berwick, R. (2014, August 26). How Could Language Have Evolved? Retrieved March 29, 2015, from http://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.1001934
Bonenfant, J. L. (2011). History of Haitian Creole: From Pidgin to Lingua Franca and English Influence on the Language. Review of Higher Education & Self-Learning, 3(11).
Christiansen, M., Reali, F., & Chater, N (2011). Biological Adaptations for Functional Features of Language in the Face of Cultural Evolution. Human Biology, 247-259.
Dediu, D., Cysouw, M., Levinson, S. C., Baronchelli, A., Christiansen, M. H., Croft, W., … & Lieven, E. (2013). Cultural evolution of language. In Cultural evolution: Society, technology, language, and religion. Strüngmann Forum Reports, vol. 12 (pp. 303-332). MIT Press.
Ellwood, C. A. (1918). Theories of cultural evolution. The American Journal of Sociology, 23(6), 779-800.
Exaptations. (n.d.). Retrieved April 25, 2015, from http://evolution.berkeley.edu/evosite/evo101/IIIE5cExaptations.shtm
Morgan, T. J. H., Uomini, N. T., Rendell, L. E., Chouinard-Thuly, L., Street, S. E., Lewis, H. M., … & Laland, N. (2015). Experimental evidence for the co-evolution of hominin tool-making teaching and language. Nature communications, 6.
Mufwene, S. (2007). What do creoles and pidgins tell us about the evolution of language? In B. Laks, S. Cleuziou, J. Demoule, & P. Encrevé (Eds.), Origin and evolution of languages approaches, models, paradigms. London: Equinox
Natural selection. (n.d.). Retrieved April 25, 2015, from http://en.wikipedia.org/wiki/Natural_selection
Orzack, Steven Hecht and Forber, Patrick, “Adaptationism”, The Stanford Encyclopedia of Philosophy (Winter 2012 Edition), Edward N. Zalta (ed.),
Smith, K., & Kirby, S. (2008). Cultural evolution: implications for understanding the human language faculty and its evolution. Philosophical Transactions of the Royal Society B: Biological Sciences, 363(1509), 3591-3603.
Snelling, A., & Matthews, M. (2013, February 26). When Was the Ice Age in Biblical History? Retrieved March 29, 2015, from https://answersingenesis.org/environmental-science/ice-age/when-was-the-ice-age-in-biblical-history/
Stout, D., & Chaminade, T. (2009). Making tools and making sense: complex, intentional behaviour in human evolution. Cambridge Archaeological Journal,19(01), 85-96.
Following our discussion on the general physical evolution of humans in the previous section, we now move on to an examination of how language are processed and understood. The cognitive niche hypothesis first advanced in Pinker & Bloom (1990) and later revised in Pinker (2010), is a consolidation of the human traits that distinguishes the natural language from other forms of animal communication. According to this framework, humans possess an innate mental state that provides them the basis for acquisition and knowledge of grammar, and to share it among themselves.
This cognitive niche includes the prerequisites of possessing a theory of mind, and also a need for social interaction. A number of scholars have proposed that the roots of theory of mind may be traced to mirror neurons and also the episodic memory in the primate brain, before it evolves into a distinctively human trait.
Though mirror neurons and episodic memory are found to be of separate systems in the human brain, both are able to give us a broader contexts for understanding the complementary functions of the human language and mind. [Back to Table of Contents]
7.2 Mirror neurons
Mirror neurons are a class of neurons which are activated as an animal executes a movement via motor control and when they imitate another individual’s (possibly conspecific) behaviour (Kilneremail & Lemon, 2013). These mirror neurons are hypothesized to be an adaptation mechanism for the understanding of actions, imitation-learning, and of associative learning. Perception and the genetic basis of human vocal imitation are suggested to be linked by mirror neurons similar to that of the monkeys in a way that is connected to the reciprocity of linguistic signs. This hypothesis is supported by some homologies discovered between the Macaque monkey’s premotor area F5 and also the human Broca’s area, as seen in Figure 5 below.
Figure 7: Mirror Neurons in the premotor cortex of macaque monkeys (indicated by red and yellow areas in A above) and in the right superior temporal sulcus of humans (indicated by red and yellow areas in B above)
Studies with Magnetic Resonance Imaging (MRI) have discovered that some cortical areas of the human brain like the inferior frontal cortex (near to the Broca’s area) are homologous to the monkey mirror neuron system. As the Broca’s area is thought to be one of the most language centered regions of the brain, one possible hypothesis is that the human language may have been evolved from the system of mirror neurons. The distinction of the mirror neuron system between monkeys and humans is that the human mirror neurons are able to be activated by linguistically related actions like reading and listening.
Human children have the ability to vocally repeat pseudowords via echolalia and speech shadowing. Such speech repetition and imitation not only helps the children to acquire new sets of vocabulary, this process of language acquisition via speech repetition is instinctive and can occur without comprehension and understanding. This suggests that the development of mirror neurons is a feature associated with a strong genetic predisposition of humans, favored by natural selection.
It is plausible that genetically pre-programmed mirror neurons was a result of a gradual process of language evolution. Improvements in cognitive mechanisms could have been selected for the mirror neurons’ ability to recognize, imitate and familiarise with complex actions. This function may account for the influence of prefrontal cortex and ventral pathways. Though there may not be concrete evidence that mirror neurons are a genetic adaptation specifically humans’, it remains that genetics may dictate the learning process of neurons and not just what they learn.
Alternatively, there is also the theory that mirror neurons are a result of associative learning instead of evolutionary adaptation. It suggests that the properties of the mirror neurons are a product, not of a genetic predisposition, but of the general processes of associative learning like conditioning procedures. The associative hypothesis conjectures that mirror neurons can also be found in other non human species. For instance, the quality of speech sounds known as formants are perceivable by many vertebrates such as primates and birds. The ability to accurately distinguish formants specific to different individuals of their species suggests that mirror neurons may also be present in animals. Specifically, a related example is the honeybees. The honeybees are able to make use of associative learning to distinguish individual human faces. When the honeybees are placed in an environment whereby the recognition of human faces are crucial, associative learning are optimized for the foraging behavior of the honeybees. Given that human faces were not originally part of the environment where the honeybee nervous systems evolved, associative learning is not an adaptation for face discrimination in honeybees (Cook et. al, 2014).
However, the associative learning is not sufficient to account for the development of mirror neurons. For instance, genetic predispositions interacts with associative learning; the associative account is unable to justify the reason why some behaviors are learnt more easily than others. Genetic predispositions hence may interact with associative learning to produce efficiency in language learning. Many experiments have also shown that human infants are inclined to imitate humans as opposed to non human actions (Bertenthal, 2014). Thus, associative learning is necessary but not an sufficient enough explanation for mirror neuron development.
It remains that the discovery of mirror neurons have result in breakthroughs in the gestural theory of speech origin. Mirror neurons in humans facilitates a direct communication between interlocutors. The actions communicated by an individual can be understood by an observer as it is able to elicit the same motor representation in their parieto-frontal mirror system. It is proposed that the mirror neurons are the basic mechanism where human language evolved. This is because it can be used to explain one of the fundamental difficulties for understanding language evolution- how messages conveyed can become valid for both the interlocutors.
According to Tulving (1972), episodic memory is an important cognitive development unique to humans. Controlled by the prefrontal medial temporal regions and posterior regions such as the posterior cingulate and retrosplenial cortex, it refers to the ability of humans to remember and re-experience past events (episodic memory) and to anticipate future events. Concerned with conscious recollection of specific past experiences, episodic memory allows humans to ‘travel’ mentally in time is important for encoding the ability for learning and retaining language skills.
This ability may have co-evolved as an adaptation with the genus Homo millions of years ago, as it allows the documentary of important historical and environmental events (cave paintings etc) , giving humans the ability to analyse and compare present, past and future scenarios.
Some features of the grammatical language may have also been derived from this pressure to communicate the timing of events (displacement) so as to strategize and enhance group survival in difficult terrains and environments. Thus this communicative cooperation amongst humans with regards to future references and planning of events may have co-evolved with symbolic communication systems.
Episodic memories are also generative, thus resulting in the productivity and creative attribute of human language. When strategizing for future events, humans have the capacity to remember and compare the different scenarios from their store of semantic concepts and episodic memories (Corballis, 2010).
Another point to note is that, more recent research has shown that there are at least some animals, notably a few primates and corvids, that exhibits the potential for episodic memory, and thus it may not be an aspect that is unique only to humans. However, more extensive research is needed to support this theory.


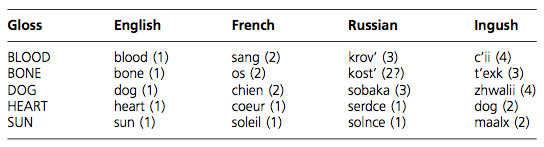

 Fig. 7. Phylogenetic tree of 400 Austronesian languages
Fig. 7. Phylogenetic tree of 400 Austronesian languages Fig. 8. The evolution of word order
Fig. 8. The evolution of word order