Contents
3.1 Using the phylogenetic method to study language evolution
3.1.1 How can phylogenetic methods be used to study language evolution?
Quantitative methods of studying language evolution requires data collection and comparison, similar to biological study of human evolution. While the study of human evolution requires comparison of physical or genetic characteristics of biological species, language evolution requires the study of linguistic data.
The concept of comparing lexical cognates in order to measure the distance between languages seem to have came from the French explorer Dumont D’Urville (Petroni & Serva, 2011). In D’Urville 1832 (cited in Petroni & Serva, 2011: 54), the French explorer used 115 lexical items and then assigned cognates a distance from 0 to 1. This list included all but three items that is in the 100-word Swadesh list that is widely used today to generate lexical distances between languages. The percentage of shared cognates between languages can be computed based on the Swadesh list in order to find out the distances between the languages of interest. Such wordlists can be used to build phylogenetic trees.
Phylogenetic analysis is based on a data matrix where the rows represent the languages to be studied and the columns represent a linguistic feature or character (Nichols & Warnow, 2008). Different languages may have different forms of a character and these are called ‘states’ of the character (Barbancon et al., 2013). There are three types of linguistic characters: lexical, phonological and morphological. For lexical characters, states correspond to cognate classes. When two or more languages are found to contain cognates, they will then be assigned the same character state.
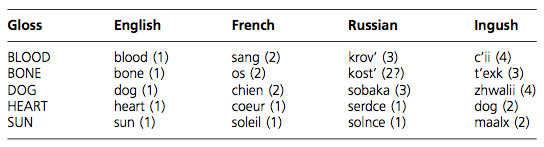
Fig. 5. Cognate classes across English, French, Russian and Ingush
(Nichols & Warnow, 2008: 765)
In Fig. 5., sun, soleil and solnce are cognates, hence they are assigned the same state, (1). Maalx is not a cognate, hence it is assigned a different state, (2).

Fig. 6. Data matrix for linguistic phylogenetic analysis
(Pagel, 2009: 405)
Data matrix M in Fig. 6. is an example of an input to phylogenetic analysis. The first column of M represents a meaning which has four distinct states or cognate classes of words (0, 1, 2 and 3), whereas the second column denotes a meaning which only have two distinct states or cognate classes (0 and 1), and so on.
For phonological characters, states represent the presence or absence of certain sound changes in the history of the language; thus phonological characters may only have two states. Morphological characters, like lexical characters, have states that correspond to cognate classes, but instead of lexicon, they represent inflectional markers. The assumption is that if two languages display the same state for the same character, they share a common ancestry. However, borrowing may result in what seems like shared inheritance but is in fact a result of language contact. Parallel development and back-mutation, which are manifestations of a phenomenon called homoplasy, can also result in shared states that cannot be attributed to shared inheritance.
Many phylogeny reconstruction methods used to generate language trees are standard methods used in molecular phylogenetics.
Distance-based methods first transforms a character matrix into a distance matrix in which distances between the languages of interest are defined. A tree is then constructed based on the distance matrix (Nichols & Warnow, 2008). UPMGA (Unweighted Pair Group Method with Arithmetic Mean) is an algorithm that repeatedly joins two languages in the matrix that have the smallest distance. This method assumes that the dataset in the character matrix produce distances that evolves like clockwork, in another words obey the lexical clock. NJ (Neighbour Joining) joins pairs of languages that has the smallest corrected (that accounts for unseen state changes) distance and it does not need the clock assumption to hold (Barbancon, 2013).
Other methods include Maximum Parsimony (MP), Maximum Compatibility (MC) and Bayesian analyses (Nichols & Warnow, 2008). MP seeks a tree on which there is the least number of character state changes whereas MC seeks a tree on which there is a maximum number of compatible (evolved without homoplasy) characters. Bayesian methods estimates the probability of each tree being the true tree and produces a probability distribution of the group of trees. The Gray and Atkinson method is one of the bayesian methods used to construct language trees.
Also, unlike phonological comparison of linguistic data, whereby the sounds of words across languages are being compared, the resemblance-based model focuses on comparing words that appear similar morphologically in languages under the same family and across different language families. These words are known as cognate sets: words in different languages that are related semantically and morphologically (Dunn et al., 2005). With the reliance on cognate sets, this would help to lay out the greater linguistic family groups that are already known, such as Indo-European, Austronesian, Sino-Tibetan and etc. On top of that, these phylogenetic trees would allow researchers to detect possible relationships between languages which are not being detected previously by manual construction of phylogenetic trees by Historical linguists.
3.2 Studies Using Phylogenetic Method
3.2.1 Studies that uses characters to construct phylogenetic trees
3.2.1.1 Language Phylogenies Reveal Expansion Pulses and Pauses in Pacific Settlement
Gray et al. (2009) investigated the origin and spread of the Austronesian language family by constructing a phylogeny of 400 Austronesian languages using lexical data and Bayesian methods. 210 lexical items including simple verbs, words for colors, numbers and animals from each of the languages were used. The origin of the Austronesian family was predicted to be in Taiwan approximately 5230 years before present. It was also revealed that the Austronesians spread through the Pacific in a series of expansion pulses and settlement pauses and this “pulse-pause” scenario is closely related with geographic expansions made possible by the availability of social and technological resources. The first pause may be attributed to the challenges in crossing the 350-km Bashi channel into the Philippines from Taiwan. The advancement in technology allowed the Austronesians to venture into new territories using new sailing modes, as seen in Pulse 1. The second pause was again, due to the difficulties in reaching far-flung islands of Eastern Polynesia. Later on, technological and social advancements have enabled the fourth pulse into Micronesia. The language phylogenies has enabled us to find many answers regarding cultural evolution and human prehistory.
 Fig. 7. Phylogenetic tree of 400 Austronesian languages
Fig. 7. Phylogenetic tree of 400 Austronesian languages
(Gray et al., 2009: 480)
3.2.2 Studies that uses phylogenetic trees to study language evolution
3.2.2.1 The Origin and Evolution of Word Order
Gell-mann and Ruhlen (2011) examined the word order of 2135 languages using a presumed phylogenetic tree of the world’s languages. They studied the distribution of the six word orders: SOV, SVO, VSO, VOS, OSV and OVS among the 2135 languages and found that the word order of the ancestral language is SOV. They suggested that most if not all of the modern languages derived from that very first SOV language and that those languages with the SOV word order simply preserved the original word order, except for languages which borrowed the word order from neighbouring languages. The large number of SOV languages today is not owing to the fact that this word order is “universally preferred” but simply because these languages inherited their word order from the ancestral language and have remain unchanged. The change in word order follows a particular pattern, that is it is almost always the case that SOV>SVO and SVO>VSO/VOS. Rare word orders like OSV and OVS may also have derived directly from SOV.
 Fig. 8. The evolution of word order
Fig. 8. The evolution of word order
(Gell-mann & Ruhlen, 2011: 17291)
3.2.3 Resemblance-based Model
3.2.3.1 Automated Similarity Judgement Program (ASJP)
Automated Similarity Judgement Program (ASJP), is a programme under the resemblance-based method, that compares two languages at a time for lexical similarity. In this research by (Brown, Holman, Wichmann & Velupillai, 2007), ASJP database consists of 100-item list of core vocabulary from a number of distributed languages, depending on the sample used by researchers. This is known as Swadesh 100-item list of core vocabulary, in which a hundred glosses or meanings are used to be comparatively analysed. This is to establish when was the point whereby two related languages started to deviate from one another and separate into different branches. “Core vocabulary” would necessarily mean words for things that appear common in the environment of human beings such as body parts, colours, and natural objects such as sun, water, rain and etc (Brown, Holman, Wichmann & Velupillai, 2007).
There are 5 steps to ASJP. First and foremost, ASJP produces Lexical Similarity Percentage (LSP) for every pair of languages that are being compared. LSP is calculated by using a formula. ASJP would detect the number of items on the list (Swadesh 100-item list of core vocabulary) in which two compared languages have words that are phonologically similar. This number of items would then be divided by the number of meanings on list for which both of the languages have words for the particular vocabulary. Thereafter, the result would be multiplied by 100. Last but not least, LSP would be corrected for confounding factors and this results in Subtracted Similarity Percentage (SSP). SSP that is generated form a database to producing ASJP trees for languages.
A diagram of ASJP would look like the following:
1.1 100-item list
For this particular research, only a subset of 100-item list of (Swadesh, 1955) consisting of 40 most stable items are being used. The method for measuring stabilities is described in (Holman, Wichmann, Brown, Velupillai, Müller & Bakker, 2008).
| Blood | Bone | Breast | Come | Die | Dog | Drink | Ear |
| Eye | Fire | Fish | Full | Hand | Hear | Horn | I |
| Knee | Leaf | Liver | Louse | Mountain | Name | New | Night |
| Nose | One | Path | Person | See | Skin | Star | Stone |
| Sun | Tongue | Tooth | Tree | Two | Water | We | You (sg) |
1.2 ASJP Orthography
Languages around the world have different writing systems which might not be an effective way to compare vocabularies for lexical similarity. Therefore, there is a need to assemble words into a uniformed, standard orthography. With the help of International Phonetic Alphabet (IPA) symbols, the vocabulary items will be simplified. A unique feature of ASJP orthography is that it consists symbols found on QWERTY keyboard that is commonly used for English Language. The underlying reason behind this is that the ASJP symbols correspond with many sounds. It is constructed to represent all sounds that appear common to languages around the world. In some languages, there are sounds that are less common and are not precisely recognised in the orthography. Such rare sounds would then be identified by the ASJP symbol that is closest to the place and manner of articulation of those sounds. It is also worth to note that the ASJP procedure is not time consuming. Most of the processes, such as formulating a standardized orthography often takes less than an hour (Brown, Holman, Wichmann & Velupillai, 2007).
1.3 ASJP Formula
1.3.1 Lexical Similarity Percentage (LSP)
No. of items on 100-item list that are phonologically similar
No. of meanings on list in which both languages have words X 100
1.3.2 Subtracted Similarity Percentage (SSP)
Subtracted Similarity (%) – Lexical Similarity (%) = Phonological Similarity (%)
2.4 ASJP Trees
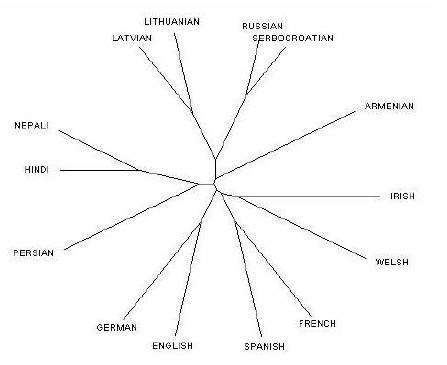
Figure 1. ASJP Tree for Indo-European Languages
(Brown, Holman, Wichmann & Velupillai, 2007).
Figure 1 illustrates the ASJP tree for certain Indo-European languages. It is imperative to note that the tree generated is not the full representation of the language families. This is due to the fact that only languages that are used in a particular research for comparative analysis will be reflected in the tree. It is evident that languages that are found on the same branch, such as German and English are more lexically similar as compared to those of different branches, such as German and Irish. Upon the construction of these trees, researchers could then compare the results produced by ASJP with the trees that are manually constructed by Historical linguists. In this particular example, there has been a mutual agreement among researchers as to the relationship found between languages found in Indo-European.
3.3 Limitations of the phylogenetic method
3.3.1
Comparison with previous analyses
The accuracy of linguistic phylogenetic trees depends heavily on the properties of the data matrix (Pompei et al., 2011). The reliability of the data matrix in turn can be affected by rapidly mutating words, the varying rate of change of meanings and undetected borrowing. Words that mutate at a very rapid rates and meanings in a language that transform at differing rates can result in the disproportionality of language distance and evolutionary distance. Furthermore, undetected borrowing can look like shared ancestry but it is actually information flowing horizontally between languages. These factors may pose as confounds to language trees and researchers may fail to account for these factors if caution is not taken.
3.3.2
Use of Simulations
Even though the generation of data could provide us a correct simulated phylogenetic tree, it does, however, suffers from the fact that the true evolution remains unknown as it only provides us a probable scenario of how languages have evolved over the years. There is a limit to how far back in time we can trace the evolution of languages and this will pose as a striking limitation.
In addition, researchers tend to evaluate the methods on a language family that is most common to them, which may be a disadvantage for languages in other language families.