

Make your research data Findable, Accessible, Interoperable, and Reusable (FAIR) in DR-NTU (Data) talk on 12 November 2019
On 12 November 2019, slightly more than 100 NTU faculty, research staff and postgraduate students from various faculties and departments attended the talk event to learn more about the latest developments in DR-NTU (Data) to support FAIR (Findable, Accessible, Interoperable & Reusable) data standards and data sharing.
The talk began with a welcome speech by Caroline Pang, Director (Office of Information, Knowledge & Library Services), who shared with the audience that since the launch of the NTU data repository DR-NTU (Data) in late 2017, more than 600 sub-dataverses, over 800 datasets and over 10,000 files have been deposited. This demonstrates NTU data depositors’ recognition of the importance of archiving and sharing their research data.
The first speaker, Sonia Barbosa, Manager of Data Curation, Harvard University emphasized the benefits of data sharing for individual researchers, research communities and society. She talked about the research life cycle, questions to consider when writing a data management plan, and good research data management. She explained the FAIR (Findable, Accessible, Interoperable & Reusable) data guiding principles and curation best practices by sharing examples of well-curated research data content in NTU data repository. Second speaker, Danny Brooke, Program Manager, Product Development, Dataverse, Harvard University excited the audience with the new and upcoming features in Dataverse which included file hierarchy, large data support, provenance (W3C), internationalization, schema.org/OpenAIRE/OAI-ORE metadata exports, make data count support, dataset external tools, previews for files, trusted remote storage agent integration, capsulation and packaging for replication objects, and redesigned dataset and file pages.
Third speaker, Ms Goh Su Nee, Lead, Research Data Management, NTU Library, shared with the audience frequently asked questions on DR-NTU (Data). Top questions being asked include: “What are the file size and number limits?”, “What NOT to deposit?”, “When shall I publish my dataset?”, and “The NTU Research Data Policy asks me to deposit my research data in DR-NTU (Data). All my research data are in my journal paper. I’m not sure what to deposit.”
If you would like to find out more on what was covered by the speakers and the questions that were posed by the audience in slido, check the links below:
Presentations slides:
- Moving Towards FAIR data sharing with The Dataverse Project by Sonia Barbosa, Manager of Data Curation, Harvard University
- The Dataverse Project by Danny Brooke, Program Manager, Product Development, Dataverse, Harvard University
- Frequently Asked Questions on DR-NTU (Data) by Ms Goh Su Nee, Deputy Director (Office of Information, Knowledge & Library Services)
1. The work of entering metadata may be very tedious, and the thought of doing it itself is…daunting. Researchers are probably not convince enough with the benefits for them to invest in time and effort of uploading the data. What can the University do to change this mindset?
Indeed, providing meaningful metadata does require time and effort. The University tries to provide support to data depositors through various metadata template and field options, as well as by providing education and consultation services. Metadata plays an important role in the discovery and reuse of published datasets. Google Dataset Search, Web of Science Data Citation Index, Google, ORCID depend on the metadata you provide for your datasets. Contact the Research Data Management Team of the NTU Library at rdm@ntu.edu.sg for training, or assistance.
2. Why should I use dataverse as compared to git based technologies (e.g. GitHub), when the latter allows me to upload data and scripts, create working copies of a repository, track changes, assign a doi, and can be synchronized with different services to have a double backup (GitHub and Gitlab)?
When you’ve data and scripts in locations such as GitHub, consider how you may leverage on DR-NTU (Data) to complement what you have in GitHub. Take a look at this DR-NTU (Data) dataset example where it has included a link to its GitHub equivalent. Consider the following potential ways to leverage DR-NTU (Data): metadata fields in DR-NTU (Data); discoverability in Google, Google Dataset Search, Web of Science Data Citation Index, ORCID; a persistent ID such as a DataCite DOI (recommended for research data); co-locating any other useful information (metadata and link to related journal paper) or additional data files or data documentation that supports reuse; versioning and data sharing license (terms) in DR-NTU (Data), etc.
3. This is concerning artworks that are in the process of being created and not yet produced and/or exhibited. How to "protect" them from plagiarism when sharing their work-in-progress? Restricting access to its files can be an option. Anything else that needs to be considered for copyright protection?
When you deposit your data (including artworks) in DR-NTU (Data), they are by default, private to you, system administrators as well as any other individuals whom you give permission to view your unpublished dataset(s) (can be configured at individual dataset level). You click ‘Publish’ only when you’re ready to share. After it’s published, it becomes Internet findable. However, if you’d like to make only the metadata of your dataset discoverable without allowing others to download your attached data files, then you are right about restricting access at the file level (please remember to do so before you publish your dataset). Alternatively, you can choose to deposit only when you are ready to publish your data. Do be mindful of NTU Research Data Policy’s requirement to safe keep research data (regardless of open or private) for at least ten years.
4. Is there any future plan to automate, or have an AI feature, that can help automate or improve the metadata entry in Dataverse?
According to Sonia/Danny, ‘We are continuing this discussion as the goal is to make self curation as easy and useful as possible. Adding to the UI more prepopulated fields, more instructions as well.
5. How will data citation can relate to researcher’s H-index?
When data is cited or reused, there’s increased chance that the data’s related research paper will be cited. According to a study done on 85 cancer microarray clinical trial publications, publicly available data was significantly associated with a 69% increase in citations, independently of journal impact factor, date of publication, and author country of origin using linear regression (Piwowar, Day & Fridsma, 2007). In another study, it was found that data made available in a public repository received 9% more citations than similar studies for which the data was not made available (Piwowar & Vision, 2013). Since the h-index is used to measure a researcher's output based on the total number of publications and the total number of citations to those publications, researchers could leverage the visibility and reusability of their published research data to draw attention to their research papers.
6. Any statistics on cited data?
Similar response to that for previous question. For more information, refer to the NTU Research Data Management Guide at https://libguides.ntu.edu.sg/rdm/whysharedata, go to section "Does it help my citation count?".
7. What’s new in FAIR?
See the latest news in FAIR: The Beijing Declaration on Research Data and
CODATA publishes the Beijing Declaration on Research Data. Another very current piece of news in FAIR: FAIR Funder Implementation Study.
8. You rarely know everything that's going to happen when you start a project. Can a DMP evolve with the project?
Absolutely. Your DMP should evolve with each new cycle of your project. It will be all the new and possibly unexpected content that took place since your last phase in the research cycle. In the NTU research information management system (RIMS), after the PI has submitted DMP for a project, PI is encouraged to update DMP anytime necessary during the project timeline. A new version will be recorded with each new update.
9. Is dataverse.org/metrics available at NTU DR? How are these developments tied to what's going on here at NTU?
Harvard has advised that NTU waits for the Harvard team to turn on the ‘Make Data Count’ in the Harvard Dataverse and make the necessary touch-ups first, before we implement it in DR-NTU (Data).
10. With more research using big data, what do you think the skill sets and resources needed to still enable and entice researchers to deposit their data?
Researchers could consider the learning and application of best practices in research data management, data archival, data presentation, FAIR data principles, the fairly new Transparency and Openness Promotion (TOP) guidelines for journals, etc. particularly subject specific ones if available.


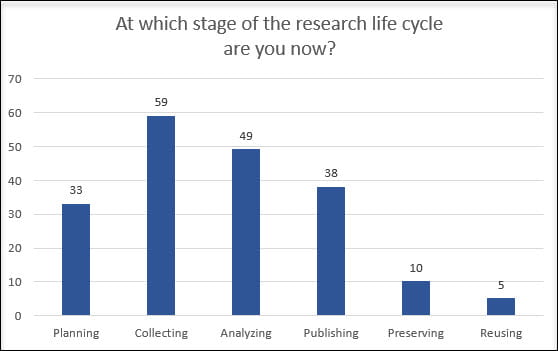
1. Can I change the data?
2. What do you do if you want to keep your data for longer than 10 years?
3. How to anonymise interview data following the best practices?
4. Unclear procedures for secure disposal of data (are there procedures at NTU?)
5. Any data anonymization tool recommended?
6. Data Use agreement, can you elaborate on it?
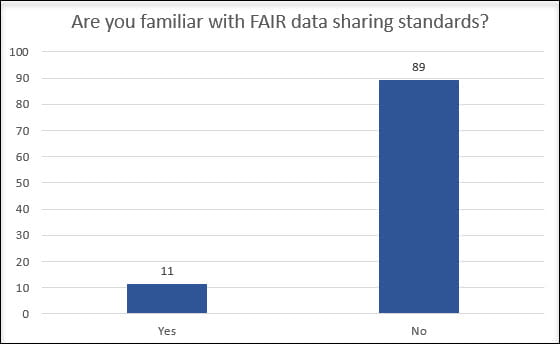
Our first speaker, Sonia Barbosa (@BlueJeansDiva) , Manager of Data Curation (@dataverseorg) will talk about what Findable, Accessible, Interoperable and Reusable (FAIR) data standards will look like in Dataverse!
Follow this thread to find out more. #DataNTUsgLibrary pic.twitter.com/hoswFDx22y— NTU Library (@NTUsgLibrary) November 12, 2019
‘Bring Your Own Data’ workshops on 11 and 12 November 2019
In addition to the talk, Sonia and Danny also conducted two ‘Bring Your Own Data’ workshops. The workshops provided closed to 40 participants hands-on experience in the depositing, description and publishing their datasets on DR-NTU (Data).
Sonia first began by giving an overview of the FAIR data guiding principles and how the Dataverse can support the research project. She went on to share the data storage, file backup and file versioning best practices, creative common licenses, and dealing with sensitive data. She showed how to curate research data by sharing examples of well-curated research data content in NTU data repository DR-NTU (Data). Next, Su Nee gave an overview of the NTU Research Data Policy by touching on ownership, rights of the principal investigators, data management plan, data deposit and sharing on NTU data repository DR-NTU (Data).
In the second part of the workshop, participants had a hands-on training by creating a sub-dataverse and dataset for themselves on the Harvard Dataverse / DR-NTU (Data) and learnt how to make their sub-dataverses and datasets more user-friendly:
- Customising the browse/search facets in their sub-dataverses to facilitate better browsing and discovery of their datasets by selecting available metadata schema
- Data files should be saved in non-proprietary (open) file formats to ensure long term accessibility where possible
- Provide relevant metadata information in the dataset template to describe their research data
We hope that the workshop participants have learnt the best practices in sharing their datasets on DR-NTU (Data).







{kind=link}